HETERMPC: A Heterogeneous Graph Neural Network for Response Generation in Multi-Party Conversations
Intro
Multi-Party Conversations
最基本的对话系统(dialogue system)基于两个对话者,这类对话被称为two-party conversation。与之相对应,更复杂、更实际的mult-party conversation意味着更多的对话参与者。在two-party conversation中,对话为一人一句交替发言的序列。而MPC中的话语可以被任何人说出,也可以在这个对话中对任何人讲话。
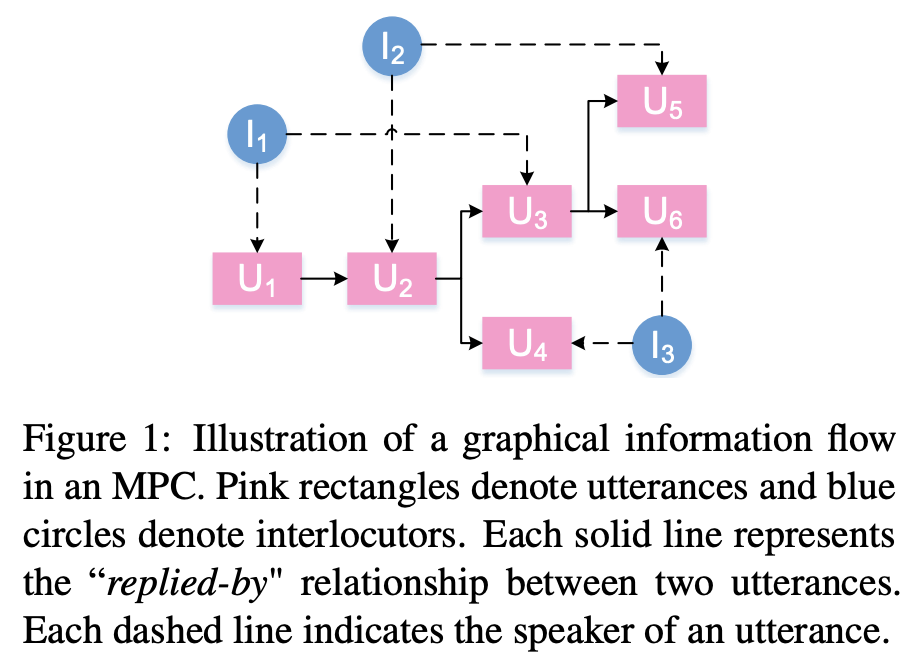
如上图所示,MPC更适合被建模为graphical information flow,而不是传统的sequence。因此,对比two-party conversation用的Seq2Seq模型,似乎用graph-structured network建模mpc更加合理。与Multi-hop的一些工作比较类似——从Entity-GCN这类同构图到后面的异构图模型——本文的主要改进也是立足于此。对比IJCAI19的模型GSN: A graph-structured network for multi-party dialogues.构建的以对话为节点的图,本文的模型构建了一个包含对话者和话语的异构图。对话者也是mpc的重要组成部分。对话者之间、话语与对话者之间存在着复杂的交互。因此,单纯的以话语为节点的图无法区分两个连接的话语节点之间的“应答”关系或“被应答”关系。
MPC中的问题生成任务是指给定对话历史,回复者以及回复的语句后,生成一个合适的回复\(r\),整个问题可以被表示为: \[ \bar{r} =\underset{r}{\operatorname{argmax}} \log P(r \mid \mathbb{G}) =\underset{r}{\operatorname{argmax}} \sum_{k=1}^{|r|} \log P\left(r_{k} \mid \mathbb{G} r_{<k}\right) . \] 其中G代表整个异构图,它包含了对话的历史信息以及待生成回复。回应的发出者和接受者是已知的,但具体内容被mask。回复语句的每个token借助自回归模型生成。\(r_k\)和\(r_{<k}\) 表示第k个token和第k-1个token。
Heterogeneous Graph
模型提出了一种基于异构图的神经网络,称为HeterMPC。首先,设计的异构图包含两种类型的节点,分别表示话语和对话者。不同于以往只对话语进行同构图建模的方法,HeterMPC对话语和对话者同时建模,使对话者之间、话语之间、对话者和对话者之间的复杂互动能够被明确地描述。为了刻画对每个(源、边、目标)三元组的异构注意,在计算注意权值和传递消息时引入了依赖于这两类节点和边的模型参数。具体地说,我们引入了六种关系来建模不同的边连接,包括两个话语之间的“回答”和“被回答”,话语与说话者之间的“说话”和“被说话者”,以及话语与接收者之间的“称呼”和“被称呼”。有了这些节点-边类型相关的结构和参数,与传统的同构图相比,HeterMPC可以更好地利用会话的结构知识进行节点表示和响应生成。最后,HeterMPC用Transformer作为其backbone,它的模型参数可以用预训练模型进行初始化。
HeterMPC Model
HeterMPC采用一种Encder-Decoder架构,多个layers堆叠用于Graph2Seq学习。图编码器的目的是捕获对话结构,并输出图中所有节点的表示,这些节点提供给解码器以生成回复。
Graph Construction
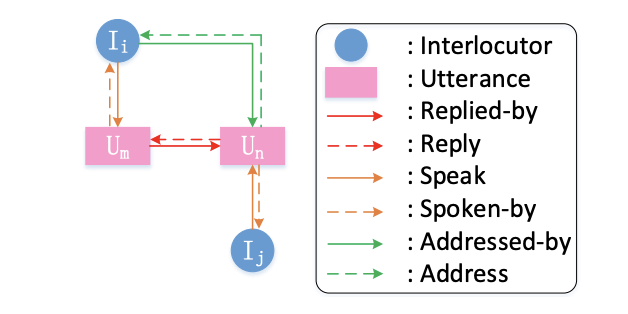
异构图用来捕获对话人以及话语间的显式交互结构。图中节点包含两类: interlocutors I和utterances M。对于不同节点间的连接,模型设计了六种类型的初始边连接{reply, replied-by, speak, spoken-by, address, addressed-by}。比如语句节点n是对另一句话m的回复,则有边\(e_{n,m}=reply\),\(e_{m,n}=replied-by\)。如果某一句话m是由谈话人i说出的,则有边\(e_{i,m}=speak\),\(e_{m,i}=spoken-by\)。如果某一句话n是针对谈话人i的,则有边\(e_{n,i}=address\),\(e_{i,n}=addressed-by\)。其他节点之间则没有边连接。
每个话语节点初始化时,节点开头会包含一个[cls],结尾会包含[sep]。而后每个utterance会输入到transformer中进行编码。说话人并不是由token构成,因此直接根据他们的说话顺序的索引进行embedding,在端到端的学习中进行更新。
Node Updating
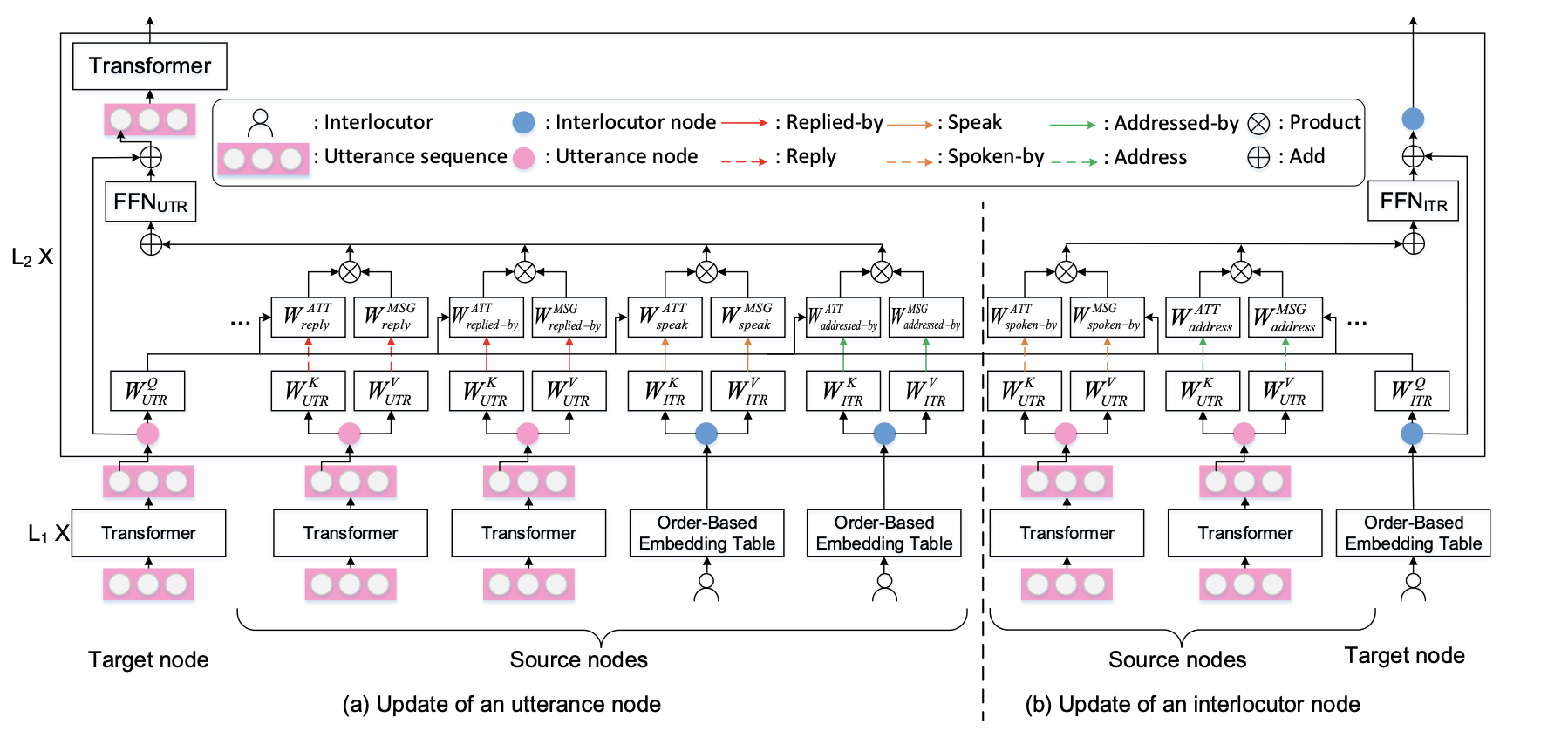
初始化的节点表示输入到构建的图中获取上下文信息进行更新,主要借助图注意力和message passing。模型架构跟Transformer比较类似,对于(s,e,t)三元组根据边类型进行attention计算,而后组合成一个向量输入到一个前向神经网络,并引入一个残差连接。 \[ \overline{\boldsymbol{h}}_{t}^{l}=\sum_{s \in S(t)} \operatorname{softmax}\left(w^{l}(s, e, t)\right) \overline{\boldsymbol{v}}^{l}(s) \] \[ \boldsymbol{h}_{t}^{l+1}=F F N_{\tau(t)}\left(\overline{\boldsymbol{h}}_{t}^{l}\right)+\boldsymbol{h}_{t}^{l} \]
Decoder

Exp
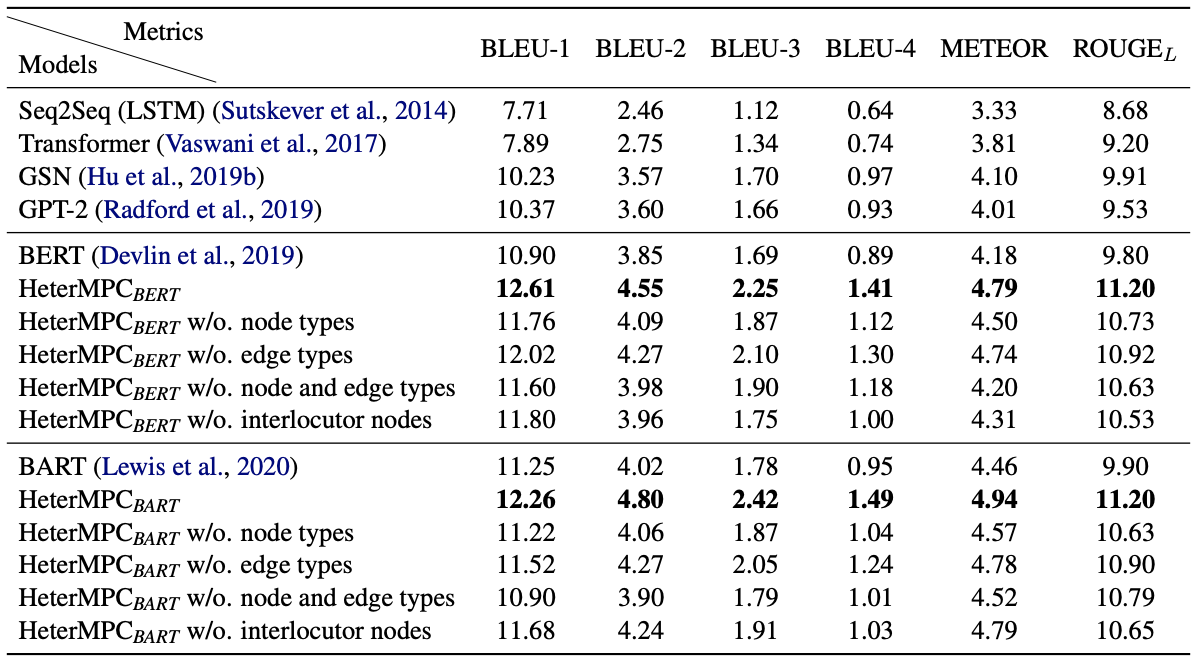

最后关于这篇论文絮絮叨叨几句。首先关于MPC这一问题,抛开生成任务不谈,其本身的信息处理过程跟multi-hop有异曲同工之处。而图结构在整个编码器中所起的作用,其实与图神经网络并不相同。与其说encoder中用的是message passing,不如说是用了attention,而在其中图结构相当于是引入了一个先验,一个拓扑结构的先验信息。虽然我们都希望大道至简,但异构图的复杂结构、边连接能比由单一类型节点构成的同构图包含更多的信息。或许我们也可以参考这类模型的设计流程,以图结构信息引入先验,而GNN则用表达能力更强的transformer的机制来替换。
