Intro
概率图模型(probabilistic graphical model)提供了一个概率与图结构结合的途径,因其灵活性、强大的表达能力和在大规模数据集中的学习和推理能力而受到广泛关注。从高层面来说,我们的目标是表示一个关于多元变量\(X = {X_1,X_2,...,X_n}\)的联合概率分布\(P\),以及边缘分布\(P(X_i)\)。但是,即便每个变量是二值变量(比如0/1),其联合概率分布的计算开销也是随着变量增加而指数级的增长。但是这些变量之间或多或少会存在一些联系,此时,我们就可以引入图结构来进行建模,借助图来直观的表示变量间的条件独立性关系,进而简化计算。两种最常见的PGM包括贝叶斯网络和马尔可夫随机场,分别为有向图和无向图。
概率图模型有三类主要问题:表示问题:对于一个概率模型,如何通过图结构来描述变量之间的依赖关系。学习问题:图模型的学习包括图结构的学习和参数的学习。推断问题:在已知部分变量时,计算其他变量的条件概率分布。
Representation
Bayesian Networks
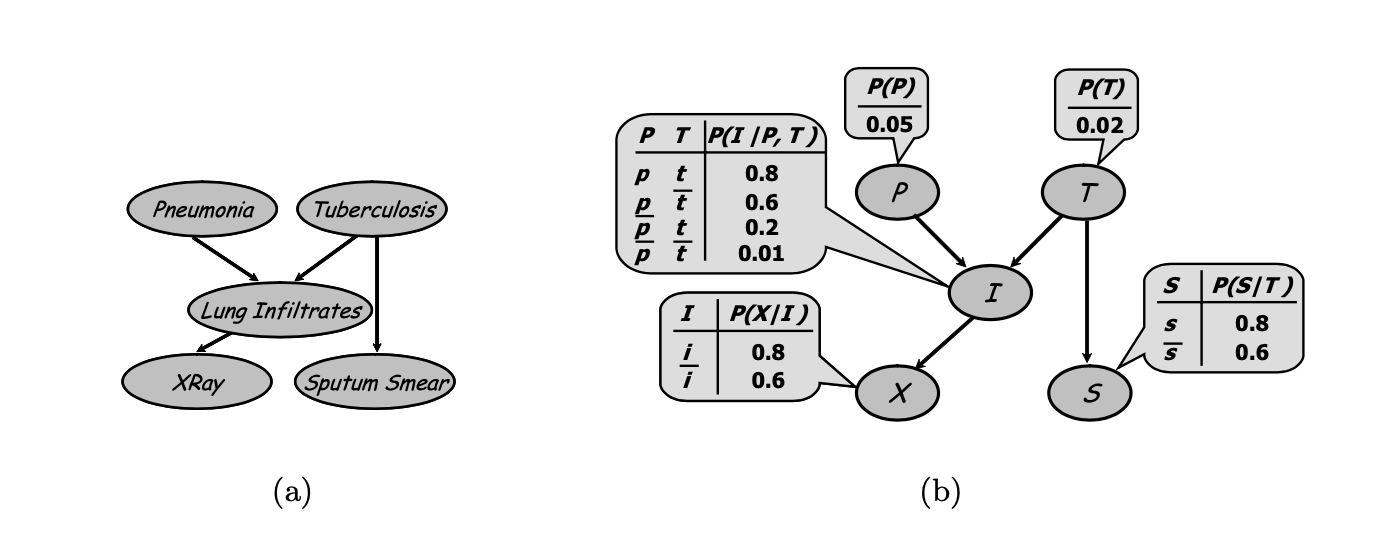
贝叶斯网络的核心结构在于有向无环图,图中的节点表示随机变量,而边则表示了变量间的关系。因此,贝叶斯网络中的节点都有一个相应的条件概率分布 \(P(X_i|Pa_{X_i})\),Pa表示父节点。此时,我们就可以得到贝叶斯网络的链式法则。 \[ P_{\mathcal{B}}\left(X_{1}, \ldots, X_{n}\right)=\prod_{i=1}^{n} P\left(X_{i} \mid \mathbf{P} \mathbf{a}_{X_{i}}\right) \] 对于贝叶斯网络,我们有条件独立性假设,即 \[ \left(X_{i} \perp \text { NonDescendants }_{X_{i}} \mid \mathbf{P} \mathbf{a}_{X_{i}}\right) \]
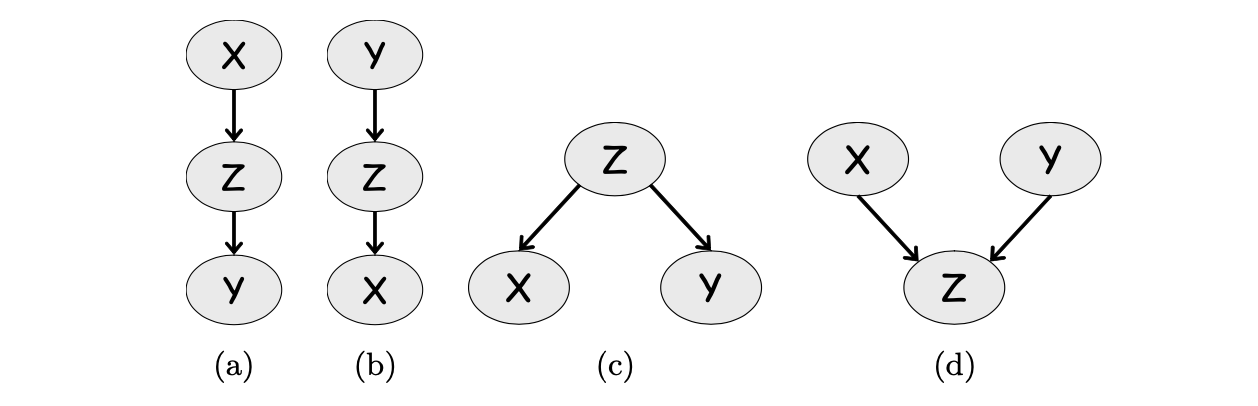 对于有向图,我们可以把变量间的概率视作一种流动的过程,考虑一个简单的三节点路径X - Y -Z如果条件概率影响可以通过Z从X流到Y,我们说路径X -Z - Y是激活的。借此可以给出在因果推断中常见的情况:
对于有向图,我们可以把变量间的概率视作一种流动的过程,考虑一个简单的三节点路径X - Y -Z如果条件概率影响可以通过Z从X流到Y,我们说路径X -Z - Y是激活的。借此可以给出在因果推断中常见的情况:
- Causal path X →Z →Y
- Evidential path X ← Z ← Y
- Common cause X ← Z → Y
- Common effect X → Z ← Y
Markov Networks
第二种常见的概率图模型称为马尔可夫网络或马尔可夫随机场,这些模型基于无向图。在独立性结构和推理任务方面,无向模型还为有向模型提供了不同的、通常更简单的视角。马尔可夫随机场的无向图允许自环存在,且满足局部马尔可夫性,即一个变量X 在给定它的邻居的情况下独立于所有其他变量。在马尔可夫随机场中,我们不能用参数化的概率或条件概率来表示一个变量,而是引入势能函数 potential function \[ \begin{array}{c} P_{\mathcal{H}}\left(X_{1}, \ldots, X_{n}\right)=\frac{1}{Z} P^{\prime}\left(X_{1}, \ldots, X_{n}\right) \\ P_{\mathcal{H}}^{\prime}\left(X_{1}, \ldots, X_{n}\right)=\pi_{i}\left[\boldsymbol{D}_{1}\right] \times \pi_{2}\left[\boldsymbol{D}_{2}\right] \times \cdots \times \pi_{m}\left[\boldsymbol{D}_{m}\right] \end{array} \] 联合分布被分解为连通子图/团的势能函数\(\pi\)的乘积,并除以一个归一化因子Z。势能函数需要满足非负性,所以一般表示为: \[ \pi[\boldsymbol{D}]=\exp (-\epsilon[\boldsymbol{D}]) \] 其中\(\epsilon[\boldsymbol{D}]=-\ln \pi[\boldsymbol{D}]\)
由于无向图模型并不提供一个变量的拓扑顺序,因此无法用链式法则对\(P(X)\) 进行逐一分解。无向图模型的联合概率一般以全连通子图为单位进行分解。 无向图中的一个全连通子图,称为团(Clique),即团内的所有节点之间都连边。
Inference
有向和无向图模型都代表了多元变量上的完整联合概率分布。对于概率图上的推理问题,我们可以理解为使用联合概率分布来回答一些query。
最常见的conditional probability query \(P(Y|E=e)\)由两部分组成:evidence E和query Y;另一种是寻找剩余变量最有可能的值 \(\operatorname{argmax}_{\boldsymbol{y}} P(\boldsymbol{y} \mid \boldsymbol{e})\)。对于以上的一些查询,最容易想到的解决方法就是得到联合概率分布,而后针对特定变量(条件概率查询)进行求和,但这一过程的计算复杂度是我们不能接受的。在这种情况下,我们选择使用概率图结构特点来进行近似推断,并考虑它产生精确结果的条件-变分推断;或者使用基于采样的近似推断来应对小数据集(比如MCMC,从后验分布生成样本)。
Learning
概率图模型的学习任务有两种:参数估计和结构学习。在参数估计任务中,我们假设图模型的结构是已知的。在这种情况下,学习任务只是学习CPD的参数或定义马尔可夫网络势能函数的参数。在结构学习任务中,不需要额外的输入(尽管用户可以提供关于结构的先验知识,例如,以约束的形式)。目标是从训练数据单独提取贝叶斯网络或马尔科夫网络结构和参数。
