Foreword
关于MUlti-QA的简介这里不多介绍,主流的Multi-QA模型大致可以根据是否包含显式/隐式的图结构分类两类,第一类借助Graph来将文本中离散的信息捕获并构建图结构(或隐式的构图),将先验信息融入图Message-passing中;第二类方法不借助图结构,而是通过Transformer直接处理长文本,或将问题分解后进行sub-question的问答。
Dynamically Fused Graph Network for Multi-hop Reasoning
在上一篇中(Multi-hop QA [1])中介绍了一篇rethinking的文章,关于图结构在多跳推理中是否是必要的,那篇文章的起源大概可以追溯到这里。具体来说,包括Entity-GCN等一系列文章都没有开源,或者开源出部分代码导致无法完全复现,但是这篇DFGN的代码开源了并且结果是完全可复现的。在广大码农复现过程中,有人发现其中的Graph Fusion模块直接使用Transformer似乎效果会更好,于是后面Is Graph Structure Necessary for Multi-hop Question Answering? 这一文章参照了DFGN的结构设计了一个baseline进行测试,发现其中的GNN确实不如Transformer表现好。(开源确实能促进这一行业的技术发展)
Inspired by human’s step-by-step reasoning behavior, DFGN includes a dynamic fusion layer that starts from the entities mentioned in the given query, explores along the entity graph dynamically built from the text, and gradually finds relevant supporting entities from the given documents.
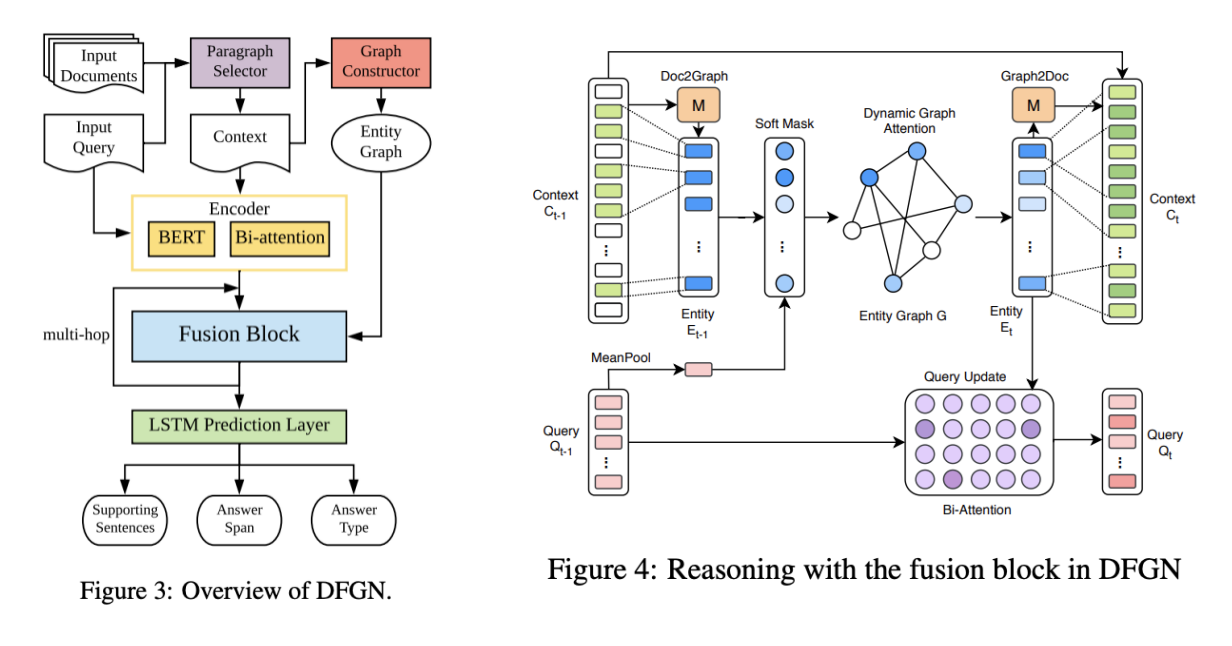
上面两个图非常直观的展现整个模型的框架,借助BERT和Graph Attention及其交互机制来获取token的表示。模型通过Doc2Graph和Graph2Doc来进行序列与图的转换。首先,候选Context和问题query一起输入BERT得到Context和query的每个token的向量表示,随后,接了一个双向注意力得到二者相互attended的表示。对于token向量,模型进行pooling后得到entity向量,而后通过Query计算实体图中每个实体的重要性并以此构建实体图。在实体图上进行Graph- attention计算图注意力。在每一层Fusion Block结束后,还会使用新的实体表示通过Bi-Attention来更新Query的表示。最后从entity反变换为context的过程Graph2Doc则是将该层最初输入的Context的表示中的每个token与其对应的实体的表示拼接然后送入LSTM。
Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
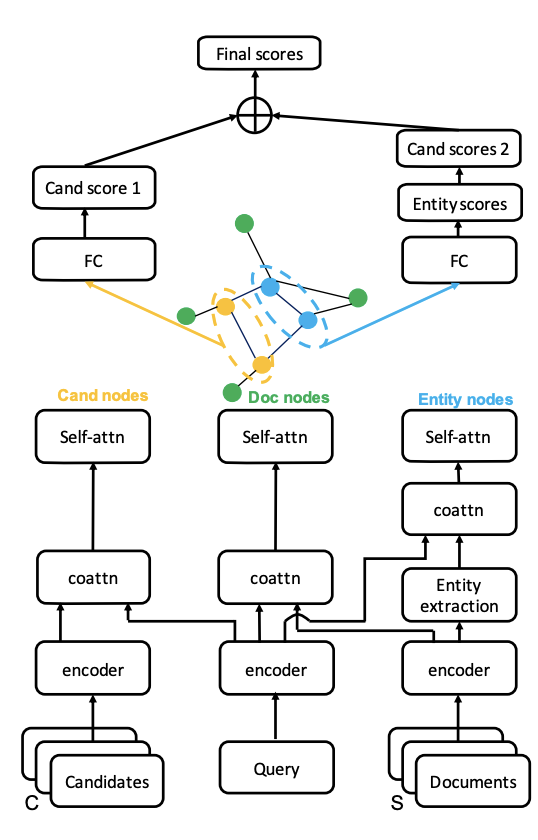
基于异构的文档-实体图。图中节点包含文档节点、实体节点、候选节点。具体节点的初始化基于co-attention 和 self-attention (这两者在Single-doc QA中非常有效)。下面介绍一下模型具体的框架,包含Encoding和Graph reasoning两个部分。
首先对于给出的query,\(<s,r,?>\)代表查询的主体,关系以及未知客体,\(S_q\)代表文档集,\(C_q\)代表候选文章。对于这三者,我们使用GloVe获取其各自的embedding \(X\)并输入到Encoder中,具体为Bi-RNN+GRU来编码上下文信息,输出为\(H\)。而后进行文档集S中的实体抽取,作为异构图中的实体节点。实体节点的embedding从相应的文档embedding中获取。接下来进行三类节点的co-attention计算,学习query和doc相互作用的embedding,具体的计算公式在这里不做呈现,总体思路跟self-attention非常类似,只不过把作用对象从token与token变为query与\(S_q/C_q\)。共同注意力用来产生文档的query-aware embedding,而self-attention pooling被设计为通过选择重要的查询感知信息将顺序上下文表示转换为非顺序特征向量。以上是Encoding部分,总体流程可以概括为初始embedding+co-atten+self-atten三个流程;而后则是进行图上的推理。
构图时,节点可以分成三类,因此在这一图上,针对不同节点之间的边定义非常复杂。模型总体包含有7类边连接,其中大部分的边定义与前人的模型是相似的。作者在后续实验时验证了不同类型边的有效性。最后图神经网络则是选择Gated-GNN。在wikihop数据集上,对比Entity-GCN,模型的准确率从71.2提升到了74.3。
LinkBERT: Pretraining Language Models with Document Links
上文提到的模型都在整个框架中显式的构建了图结构,并通过图上的message passing来进行消息的传播,但是这篇模型则是借助图结构来辅助Bert进行更好的上下文理解,进而直接对多段文本进行学习。
目前的language model输入的文本仅来源于单一文档的上下文。LinkBert将不同的文档间建立连接,输入的上下文来源于相连的文档。另外,模型的训练将NSP任务 变为对应的document relation prediction (DRP)。对比原始的Bert,基于LinkBERT构建的LM对解决multi-hop QA有天然的优势。 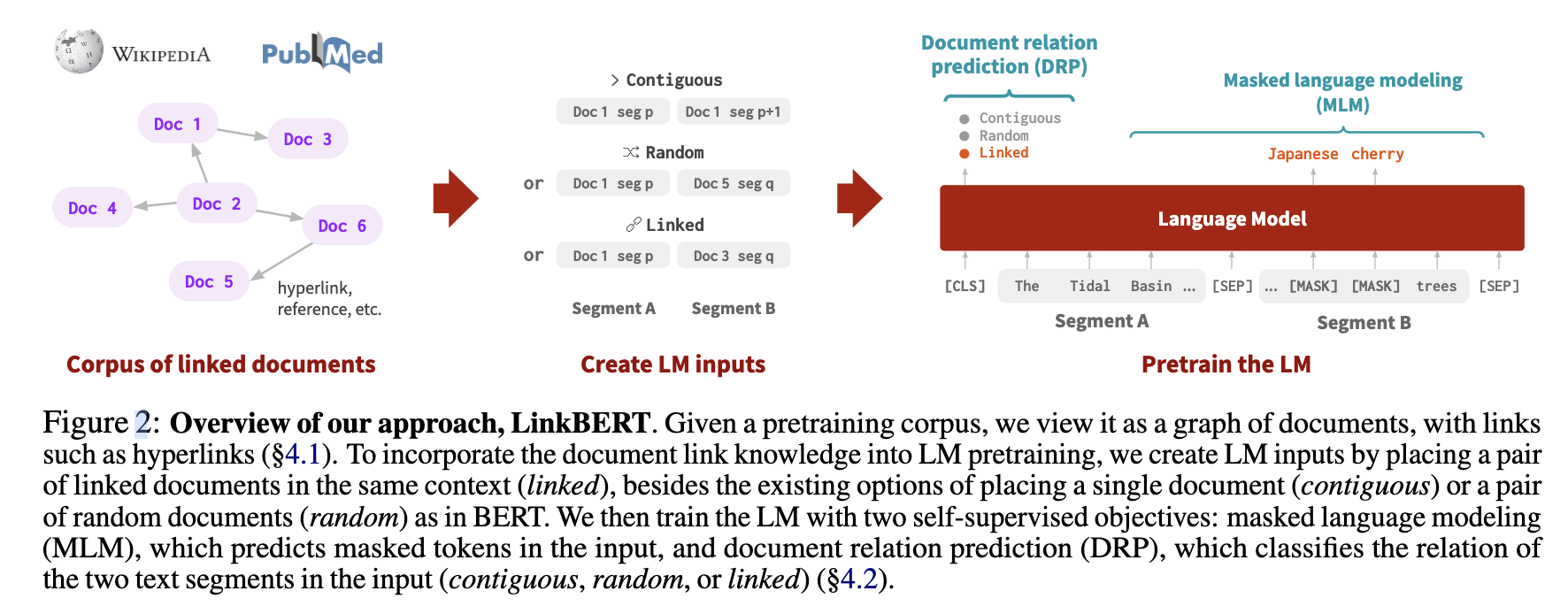
输入的数据为 $ [CLS]X_A[SEP]X_B[SEP]$ 形式,\(X_{A/B}\)为文档片段,对于一个Segment A,其后接的Segment B有三种选择:1.A后的连续片段B;2.随机文档的片段B;3.与文档A有hyperlink的文档的片段B
文档片段之间的链接建立需要考虑一些信息,包括:关联性,可以通过使用超链接或词汇相似性度量来实现;链接的文档是否可以提供当前的LM可能看不到的新的、有用的知识。在这方面,超链接可能比词汇相似性链接更有优势;多样性。在文档图中,一些文档可能具有非常高的程度(例如,许多传入的超链接,如维基百科的美国页面),而其他文档可能具有较低的程度。如果我们从每个锚段的链接文档中统一采样,可能会在整体训练数据中过于频繁地包含程度较高的文档,从而失去多样性。为了调整使所有文档在训练中以类似的频率出现,我们以与其程度成反比的概率对链接文档进行采样。
Ask to Understand: Question Generation for Multi-hop Question Answering
该模型解决Multi-hop QA的思路更贴近人类的逻辑推理过程,将问题根据线索进行分解,而后解答子问题。但是这于这类模型,子问题的生成质量非常关键,因此模型引入了额外的 QG 任务来训练模型的问题生成部分。具体来说,我 们在经典的基于GN的模块的基础上精心设计并添加了一个端到端的QG模块。对比传统的基于QD的方法只依赖问题带来的信息,我们提出的QG模型可以同时基于对原始上下文和问题的理解来生成流畅的、含有内在逻辑的子问题。 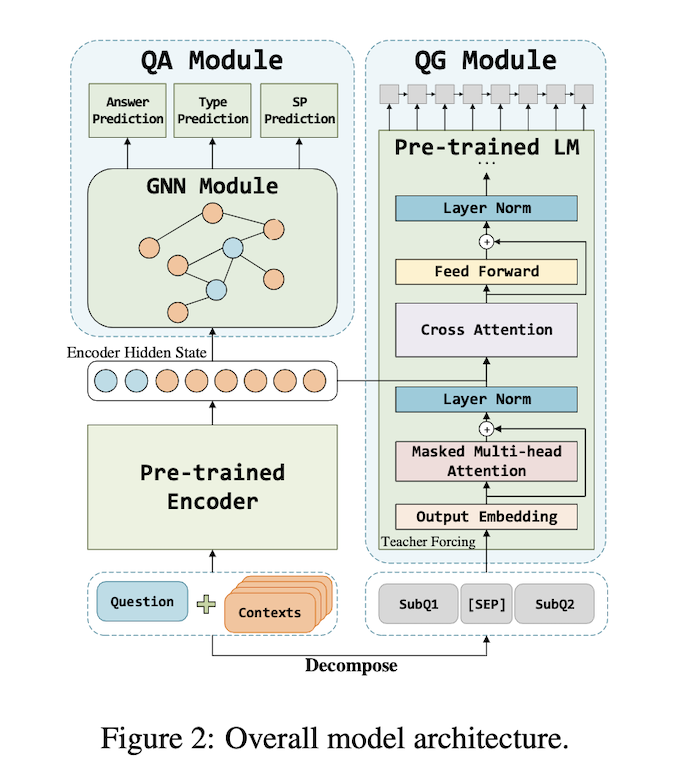 对于QA模块,模型采用常规的Encoder+GNN的结构,但是QG辅助的作用体现在Encoder会与QG模块贡献,GNN采用的是与DFGN相同的架构;QG模块的整体架构如上图,主要问题在于针对性的数据集的获取,即如何获取训练的子问题。作者提到HotpotQA数据集中大概可以被分类两类问题:Bridge 和 Comparison 其中第一种需要从first-hop中查找线索而后推理下一个目标,后者则是对query中提到的两个实体性质进行比较。
对于QA模块,模型采用常规的Encoder+GNN的结构,但是QG辅助的作用体现在Encoder会与QG模块贡献,GNN采用的是与DFGN相同的架构;QG模块的整体架构如上图,主要问题在于针对性的数据集的获取,即如何获取训练的子问题。作者提到HotpotQA数据集中大概可以被分类两类问题:Bridge 和 Comparison 其中第一种需要从first-hop中查找线索而后推理下一个目标,后者则是对query中提到的两个实体性质进行比较。
Kristine Moore Gebbie is a professor at a university founded in what year?这是一个Bridge问题,先找到university再找到成立年份;Do The Importance of Being Icelandic and The Five Obstructions belong to different film genres?这是comparison问题,包含The Importance of Being Icelandic、Five Obstructions、film genre三个实体,这时问题则会被分解为Do The Importance of Being Icelandic belong to which film genres? 与Do The Five Obstructions belong to which film genres?
