Question Answering by Reasoning Across Documents with Graph Convolutional Networks
Is Graph Structure Necessary for Multi-hop Question Answering?
Big Bird: Transformers for Longer Sequences
图结构QA
 多跳问答可以看作一个多步推理以及信息结合的过程,Entity-GCN借助图结构的节点建模文本的实体,将其转化为图上的推理问题,取得了非常好的结果。另外,作者提到虽然multi-hop是一个非常具有实际意义的问题,但在此之前的模型仅仅是将文档连接为长文本,而后借助RNN类的模型进行处理。
多跳问答可以看作一个多步推理以及信息结合的过程,Entity-GCN借助图结构的节点建模文本的实体,将其转化为图上的推理问题,取得了非常好的结果。另外,作者提到虽然multi-hop是一个非常具有实际意义的问题,但在此之前的模型仅仅是将文档连接为长文本,而后借助RNN类的模型进行处理。
对于QA问题,给定一个文档集合和查询,我们要从多个候选回答中选择正确的答案(实体)。其可以表示为\(\left\langle q, S_{q}, C_{q}, a^{\star}\right\rangle\),\(q\)表示问题,\(S_{q}\) 表示supporting document,\(C_{q}C\)表示候选的entity 集合,\(a_*\)是\(q\)的答案。本文的目的是训练一个神经网络,给定一个查询\(q\),可以输出答案在\(C_{q}\)上的一个概率分布。通过最大似然估计模型的参数,输出概率最大的结果作为预测的问题答案。
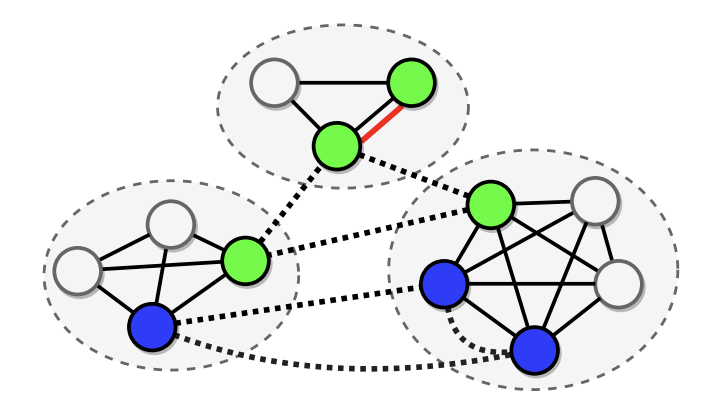
对于一个query,\(q=\langle s, r, ?\rangle\),我们根据supporting documents构建图,其中的节点或为查询的实体,或为候选实体。上图中同样颜色的节点代表同一实体,节点之间的边根据三种规则构建:在同一文档中共现(实线),不同的mentions之间实体匹配(虚线),coreference(红线)。接着借助构建的图进行图卷积(Gated-GCN),得到候选节点的特征,并将其与问题的特征结合,作为候选实体的估计。模型encoding的预处理用了ELMo。 \[ P\left(c \mid q, C_{q}, S_{q}\right) \propto \exp \left(\max _{i \in \mathcal{M}_{c}} f_{o}\left(\left[\mathbf{q}, \mathbf{h}_{i}^{(L)}\right]\right)\right) \]
深入分析
Entity-GCN的成功以及当时GNN在NLP领域的热度让人们开始竞相探索图在多步推理上的应用。大部分的工作都将分布在不同段落间的实体抽取并建模为图结构。Is Graph Structure Necessary for Multi-hop Question Answering? 这篇文章的作者基于HotpotQA数据集构建了一个强大的基线模型并证明了,通过正确地使用预训练模型,图结构对于多步推理问答是不必要的。他们认为图结构和对应的邻接矩阵都可以被看作是一种任务相关的先验知识,并且图注意力可以被看作是自注意力的一种特例。实验和可视化分析都表明图注意力或整个图结构都可以被自注意力或Transformer替代。
论文提到基于图结构进行多跳问答的模型有很多变种,包括借助有向图的循环层来建模实体间的关系,使用动态实体图来解决抽取式的多步推理问答任务以及引入文档节点和问题节点将实体图拓展为异构图等方法。然而,作者在实验中发现移除图结构并不会影响模型的最终效果。
这里放一下原论文作者写的博客:EMNLP 2020 | 多步推理问答是否真的需要图结构?
这里简单介绍一下论文思路,具体细节可以参考原论文以及上面的博客。作者借助Bert和GCN构建了一个基线模型,如下图所示  模型使用RoBERTa进行上下文的编码,借助Bert进行命名实体识别构建图结构,实体图的连接规则由以下两条规则确定:1)上下文中不同位置出现的相同实体之间有连接。2)同一个句子中出现的不同实体之间有连接。(这里有待考量,下文细🔒)。在HotpotQA数据集上,这个模型取得了非常好的表现:
模型使用RoBERTa进行上下文的编码,借助Bert进行命名实体识别构建图结构,实体图的连接规则由以下两条规则确定:1)上下文中不同位置出现的相同实体之间有连接。2)同一个句子中出现的不同实体之间有连接。(这里有待考量,下文细🔒)。在HotpotQA数据集上,这个模型取得了非常好的表现:  基于这个模型进行后续实验时,作者发现在预训练模型以fine-tuning的方式使用时,包含和不包含图结构的模型都取得了相似的结果。而当我们固定预训练模型的参数后,EM和F1显著下降了9%和10%。如果此时进一步移除图结构,EM和F1会进一步下降4%左右。换句话说,只有当预训练模型以Feature-based的方式使用时,图结构才会起到比较明显的作用。而当预训练模型以Fine-tuning的方式使用时(这是较为通常的方式),图结构并没有对结果起到贡献,换句话说,图结构可能不是解决多步推理问题所必要的结构。
基于这个模型进行后续实验时,作者发现在预训练模型以fine-tuning的方式使用时,包含和不包含图结构的模型都取得了相似的结果。而当我们固定预训练模型的参数后,EM和F1显著下降了9%和10%。如果此时进一步移除图结构,EM和F1会进一步下降4%左右。换句话说,只有当预训练模型以Feature-based的方式使用时,图结构才会起到比较明显的作用。而当预训练模型以Fine-tuning的方式使用时(这是较为通常的方式),图结构并没有对结果起到贡献,换句话说,图结构可能不是解决多步推理问题所必要的结构。
而后作者提到,图注意力是self-attention的一种特例,用transformer代替两层图神经网络也能取得非常接近的结果。作者指出邻接矩阵和图结构都可以被看作是一种任务相关的先验知识。
不过笔者私以为,既然作者认为图结构、领接矩阵是一种先验知识,那借助图神经网络可以很好的将这些先验融入到深度神经网络中。另一方面,其实图神经网络的表现很大程度上与图的构建有关,而作者在实验时只采用了这种非常naive的构图思路,而后说明这种图结构是没有作用的,感觉这里的论证略显单薄。另一方面,将先验知识结合到feature中,借助图神经网络的message passing机制进行学习和反向传播,从而将先验知识的融入纳入到神经网络这一框架下,也可以说是体现了图结构的意义。
Transformer plus
上文提到,图注意力和图结构可以被自注意力或Transformer替代,也就是说基于图结构的模型本质上与Transformer是相似的。
 Transformer中最重要的就是Self-attention机制,从上图可以看到,而self-attention的计算包括Q、K、V三个矩阵以及矩阵乘法,此时就会引出一个复杂度问题。 \[
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
\] Q、K点乘的内存、速度是序列长度的平方复杂度。对于输入为长文本时,我们一般做法是切成512的块,这种做法损失了块与块之间的信息,比如多跳QA问题或者长文本文本摘要,块与块之间的信息起了重要的作用。
Transformer中最重要的就是Self-attention机制,从上图可以看到,而self-attention的计算包括Q、K、V三个矩阵以及矩阵乘法,此时就会引出一个复杂度问题。 \[
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
\] Q、K点乘的内存、速度是序列长度的平方复杂度。对于输入为长文本时,我们一般做法是切成512的块,这种做法损失了块与块之间的信息,比如多跳QA问题或者长文本文本摘要,块与块之间的信息起了重要的作用。
针对这一问题,解决的方法主要可以分为两类,第一类接受长度的限制,寻求绕过这一问题的方法:比如对文本使用滑窗,或者从上下文中选择一个subset输入到transformer中,而后迭代不同的上下文。基于这一思路的模型有: SpanBERT, ORQA, REALM, RAG等。另一类方法认为full attention是没有必要的,这类 Sparse Attention Mechanism就包括Longformer、Big Bird。 

从上图就可以看出,这些方法抛弃了原有的全局attention计算,变为几类attention,包括:
random attention:对于每个Q,都等概率随机关注r个Key。
window attention:对于每个Q,都关注相邻的左边w/2个Key,右边w/2个key。这是因为直觉上告诉我们,多数NLP问题上下文更加重要。
global attention:在一些预先选择的输入位置上添加全局attention,使这些位置能够关注所有的信息,比如图上所显示的使传统Bert在做分类时,[CLS] token就使用了global attention。针对QA问题时,我们就可以令问题部分的token为global attention。
Big Bird就是使用了这三类Attention,实验结果上也证明了这类模型比传统的Bert表现更好。 
