link: https://arxiv.org/abs/2105.03075v4
数据增强的背景
什么是数据增强?
Data augmentation (DA) refers to strategies for increasing the diversity of training examples without explicitly collecting new data.
作者提到,数据增强是一种在不收集新数据的前提下增强训练样本多样性的策略。从这里可以看出,首先数据增强是根据已有的数据来创造新数据的过程。其次,数据增强并不意味着单纯地增多数据,而是为了模型训练进行服务的。也就是说,我们要在任务目标指导下借助已有的样本来创造新样本。
为什么要做数据增强
当我们获得的数据有限,不足以训练出优秀的模型时,就需要获取更多的数据。但是采集新数据往往要消耗大量的人力物力资源,在这种情况下,数据增强技术就提供了一个很好的解决措施,尤其是现在NLP领域基本是大规模预训练模型大行其道,对大数据更加渴求。而令一方面,数据增强能够按照我们的意愿对数据做一些约束。换句话说,我们可以通过数据增强的方法引入一些先验知识或条件。
数据增强的合理性
从我们直观的角度思考,扩充数据的分布与原始数据的分布既不应该太相似,也不应该太不同。我们设计的数据增强方法得到的新数据是尽可能服从实际情况下的分布。此时,在样本空间上更多的采样点有助于我们进一步探索真实的数据分布。
data augmentation is typically performed in an ad- hoc manner with little understanding of the under- lying theoretical principles
作者提到,目前关于DA为什么有效的研究工作主要停留在表层,对其理论基础和原理研究较少。一些现有的工作包括: 带噪声测试样本的训练可简化为Tikhonov正则化;DA可以增加分类器的positive margin,但只有在许多常见DA方法以指数方式做数据增强时才会如此;将DA转换视为kernels,并发现DA的两种帮助方式:特征平均和方差正则化。
Data Augmentation in CV
常见的CV中的数据增强包括:
旋转、平移、翻折
缩放:图像可以被放大或缩小。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像 进行裁切。
随机裁剪,我们随机从图像中选择一部分,然后降这部分图像裁剪出来,然后调整为原图像的大小
添加噪声: 过拟合通常发生在神经网络学习高频特征的时候 (因为低频特征神经网络很容易就可以学到,而高频特征只有在最后的时候才可以学到) 而这些特征对于神经网络所做的任务可能没有帮助,而且会对低频特征产生影响,为了消除高频特征我们随机加入噪声数据来消除这些特征。

相较于机器学习和计算机视觉领域,数据增强在NLP应用并没有前两者这么广泛。在NLP中,输入空间是离散的,我们需要关注如何生成有效的增广例子来捕获所需的不变性。因此它通常被比喻成“蛋糕上的樱桃”,只是提高有限的性能。
主流技术
理想的DA技术应该既易于实现又能提高模型性能,但我们往往需要在这两者之间进行权衡。基于规则的技术很容易实现,但通常只能带来有限的性能改进。基于训练的模型的DA技术可能代价更大,但会引入更多的数据变化,导致更好的性能提升。为下游任务定制的基于模型的DA技术对性能有很强的影响,但很难开发和利用。
Rule-Based Techniques
在特征空间内直接进行变化生成新的样本,比如在已知类别的数据之间进行“类比”转换,以扩充新的类;使用迭代的仿射变换和投影来沿着class-manifold最大限度地“拉伸”一个样本。
还有比如我们可以借助单词嵌入,如Word2Vec, GloVe, FastText, Sent2Vec,使用嵌入空间中最近邻的单词替换句子中的某个单词。 
EASY DATA AUGMENTATION (EDA):token-level的随机扰动操作,比如随机插入、删除、交换以及同义替换等。作者发现经过EDA后文本分类的准确率有了很大的提升。

Unsupervised Data Augmentation (UDA)。一种基于无监督数据的数据增强方式,该方法通过对\((x, DA(x))\)进行consistency training,生成无监督数据与原始无监督数据具备分布的一致性 
在数据上构建带标记的图,将单个句子作为节点,配对的标签作为带标记的边。使用平衡理论和及物性从这个图中推断扩充句子对。 
Dependency tree morphing DA:受图像裁剪和旋转的启发,Şahin和Steedman提出了依赖树构建方法。对于带有依赖项注释的句子,可以交换或删除具有相同父节点的子节点。 
Example Interpolation Techniques
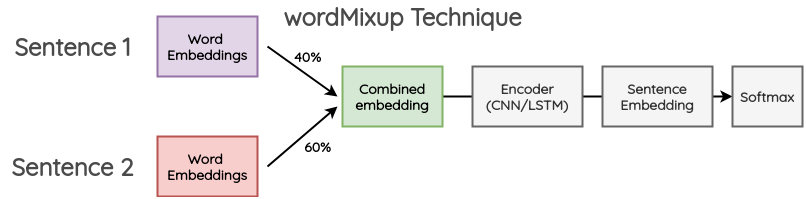
Mixed Sample Data Augmentation (MSDA) /MixUp。这种插值方法在图像处理领域应用非常广泛
\(\tilde{x}=\lambda x_{i}+(1-\lambda) x_{j}, \quad\) where \(x_{i}, x_{j}\) are raw input vectors
\(\tilde{y}=\lambda y_{i}+(1-\lambda) y_{j}, \quad\) where \(y_{i}, y_{j}\) are one-hot label encodings
不同于MSDA这种连续插值,CUTMIX用从图像B中采样的一个patch替换图像A中的一个小的子区域,标签按照子区域大小的比例混合。对于NLP来说,例如涉及图像和文本的多模态问题可以借鉴这一工作的思想。
SEQ2MIXUP:(sequence-level variant of MixUp)对于sequence-to-sequence的模型,将输入/输出序列对进行一定的组合。 \[ \begin{array}{r} (\hat{X}, \hat{Y})=\left(m_{X} \odot X+\left(1-m_{X}\right) \odot X^{\prime}\right. \\ \left.m_{Y} \odot Y+\left(1-m_{Y}\right) \odot Y^{\prime}\right) \end{array} \]
\(m=\left[m_{X}, m_{Y}\right]\)是一个系数向量。这种方法对于基于transformer的机器翻译、语义解析等任务都有明显的提升。
Model-Based Techniques
Seq2seq model以及language model都可以被用来做数据增强。
DiPS 原本是用于Diverse Paraphrasing(复述)任务的模型,该任务的度量标准为语义的相似性以及句子本身的差异性,但是我们也可以借助这些模型来进行数据增强。 
类似的基于Transformer、BERT的模型从预训练的嵌入空间中,使用上下文敏感的、基于注意力的语义邻居混合来增强单词表示。
,如果需要预训练模型(如BERT),则需要预训练。Preprocess表示需要进行预处理,Level表示数据被DA修改的深度,Task-Agnostic表示DA方法是否可以应用于不同的任务。Ext.Know、KWE、tok、const和dep分别代表外部知识、关键字提取、字符化、分组解析和依赖解析。")
应用
Low-Resource Languages && Few-Shot Learning
低资源语言是DA的一个重要和具有挑战性的应用,尤其是神经机器翻译(NMT)。使用外部知识的技术很难将高资源语言用于低资源语言,特别是当它们具有相似的语言属性时。
 如上图所示,我们可以借助一个high-resource language作为中枢来转化目标语言以及low-resource language。当high-resource language与low-resource language属于相同语系或具有类似性质时,我们将(HRL-ENG)数据集借助数据增强转化为(LRL-ENG) 数据集。对于其他任务,我们也可以通过DA来扩充low-resource language。
如上图所示,我们可以借助一个high-resource language作为中枢来转化目标语言以及low-resource language。当high-resource language与low-resource language属于相同语系或具有类似性质时,我们将(HRL-ENG)数据集借助数据增强转化为(LRL-ENG) 数据集。对于其他任务,我们也可以通过DA来扩充low-resource language。
Mitigating Bias && Fixing Class Imbalance
以性别的偏差为例,可以借助DA来缓解性别偏见:创建一个与原始数据相同但偏向于未被充分代表的性别的增强数据集(使用实体的性别交换,如将“他”替换为“她”)来缓解引用解析中的性别偏见,并对这两个数据集进行联合训练。后续也有更好的工作比如缓解性别偏见的COUNTERFACTUAL DA (CDA)方法来打破性别词和中性词之间关联的因果干预。
类似也可以用于解决某些类别中的采样不足和采样过度问题。比如通过插值增强少数群体类的例子,以平衡多标签分类的分类。
当前挑战和未来研究方向
应用到数据增强的NLP任务有很多,首先最基本的就是分类,这也是用来测试数据增强技术效果的基本方式之一。其他的任务包括摘要、问答、序列标注、Data-to-Text自然语言生成等以及多模态的任务如automatic speech recognition。
但是目前为止的研究存在以下方面的缺陷:
明显缺乏关于DA为什么有效的研究。大多数研究都根据经验表明,以及基于一些实验表明DA技术是有效的,但目前很难在不诉诸于全面实验的情况下衡量技术的优劣。
多模态领域做数据增强。尽管多模态数据分析的工作有所增加,但许多研究都集中在单个模态或多个模态的扩展上。任需进一步探索诸如图像和文本同时增强的图像字幕方式。
基于范围的任务。例如,随机token替换可能是局部可接受的DA方法,但可能会破坏后面句子的共引用链。此时DA技术必须考虑文本中不同位置之间的依赖关系。
在专业领域工作,比如那些具有特定领域词汇和术语的领域(如医学),许多预先训练的模型和外部知识不能被有效地使用。研究表明,当应用于特定领域数据时,DA变得不那么有效,这可能是因为增广数据的分布可能与原始数据有很大不同。
另一方面,针对数据增强所应对的少样本问题,我们还能从半监督学习角度考虑,结合数据增强与半监督学习技术是一个不错的选择。半监督学习能够充分利用大量未标注数据,同时能够使输入空间的变化更加平滑。
补充材料
一些关于NLP中数据增强方法具体操作的介绍: https://amitness.com/2020/05/data-augmentation-for-nlp/
NLP数据增强工具包:nlpaug
类似的综述性文章:
Data Augmentation Approaches in Natural Language Processing: A Survey
