前情提要
在前面两篇Blog(中文分词1、中文分词2)介绍了关于中文分词的基本方法以及近年来基于深度学习的部分分词模型,即基于字符的分词技术,接下来讲介绍基于词的中文分词模型。
基本框架
Neural Word Segmentation Learning for Chinese
 基于的框架如上图所示,不同于基于字符标注的模型,基于词的模型根据字符向量生成词向量。具体而言,模型得到输入的字符向量后,使用一个Gated Combination Neural Network,将L个字符向量组合,生成候选词向量: \[
\mathbf{w}=g\left(\mathbf{W}^{(L)}\left[\begin{array}{c}
\mathbf{c}_{1} \\
\vdots \\
\mathbf{c}_{L}
\end{array}\right]\right)
\]
基于的框架如上图所示,不同于基于字符标注的模型,基于词的模型根据字符向量生成词向量。具体而言,模型得到输入的字符向量后,使用一个Gated Combination Neural Network,将L个字符向量组合,生成候选词向量: \[
\mathbf{w}=g\left(\mathbf{W}^{(L)}\left[\begin{array}{c}
\mathbf{c}_{1} \\
\vdots \\
\mathbf{c}_{L}
\end{array}\right]\right)
\]
\(\mathbf{W}^{(L)}\)是一个所有词共享的权重。这GCNN中包含reset gate 和 update gate。
\[ \mathbf{w}=\mathbf{z}_{N} \odot \hat{\mathbf{w}}+\sum_{i=1}^{L} \mathbf{z}_{i} \odot \mathbf{c}_{i} \]
\[ \hat{\mathbf{w}}=\tanh \left(\mathbf{W}^{(L)}\left[\begin{array}{c} \mathbf{r}_{1} \odot \mathbf{c}_{1} \\ \vdots \\ \mathbf{r}_{L} \odot \mathbf{c}_{L} \end{array}\right]\right) \]
\(\mathbf{W}^{(L)} \in \mathbb{R}^{d \times L d}\) 和 \(\mathbf{r}_{i} \in \mathbb{R}^{d}(1 \leq i \leq L)\) 表示reset gates,用来决定字符向量的哪部分被结合到词向量中: \[ \left[\begin{array}{c} \mathbf{r}_{1} \\ \vdots \\ \mathbf{r}_{L} \end{array}\right]=\sigma\left(\mathbf{R}^{(L)}\left[\begin{array}{c} \mathbf{c}_{1} \\ \vdots \\ \mathbf{c}_{L} \end{array}\right]\right) \] 而update gate则是 \[ \left[\begin{array}{c} \mathbf{z}_{N} \\ \mathbf{z}_{1} \\ \vdots \\ \mathbf{z}_{L} \end{array}\right]=\exp \left(\mathbf{U}^{(L)}\left[\begin{array}{c} \hat{\mathbf{w}} \\ \mathbf{c}_{1} \\ \vdots \\ \mathbf{c}_{L} \end{array}\right]\right) \odot\left[\begin{array}{c} 1 / \mathbf{Z} \\ 1 / \mathbf{Z} \\ \vdots \\ 1 / \mathbf{Z} \end{array}\right] \] 其中\(\mathbf{U}^{(L)} \in \mathbb{R}^{(L+1) d \times(L+1) d}\) 是系数矩阵,\(\mathbf{Z} \in \mathbb{R}^{d}\)是归一化向量。
得到候选词向量之后,每个输入句子中的词向量会被转化为一个分数word_score,代表这个词有多大的可能性是一个真实存在的词。这些word_score会与经过LSTM之后的词向量共同组合成sentence score。
得到分数之后,之前多数序列标注的分词方法多使用Viterbi算法进行动态规划,得到最优的分词方法,但是在这个模型中,由于可能的句子分词方式总数太大,且为了捕捉完整的分割决策(不同于基于字符标注的方法),模型使用了Beam Search算法作为Decoder。
改进模型
Fast and Accurate Neural Word Segmentation for Chinese
首先,这篇文章的作者对字符生成候选词向量的GCNN网络进行了改进。模型引入了一个高频词词典,在词典中则直接对character embedding进行average pooling,而不在词典中则根据构成的字符向量生成词向量,如下图所示 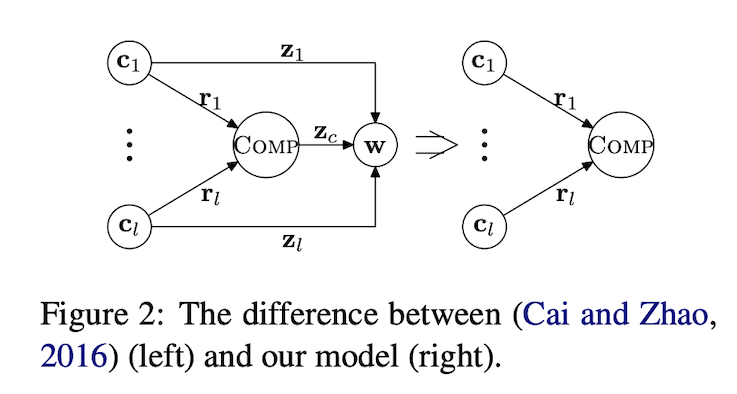 \[
\operatorname{COMP}\left(c_{1} . . c_{l}\right)=\tanh \left(\mathbf{W}_{l}^{c}\left[\mathbf{r}_{1} \odot \mathbf{c}_{1} ; \ldots ; \mathbf{r}_{l} \odot \mathbf{c}_{l}\right]+\mathbf{b}_{l}^{c}\right)
\] \[
\left[\mathbf{r}_{1} ; \ldots ; \mathbf{r}_{l}\right]=\operatorname{sigmoid}\left(\mathbf{W}_{l}^{r}\left[\mathbf{c}_{1} ; \ldots ; \mathbf{c}_{l}\right]+\mathbf{b}_{l}^{r}\right)
\] 作者讲gate mechanism进行了简化,使得模型训练更加快速。另外,原模型中的Beam Search也改为了贪心算法,采用了两种训练方法:Early update、LaSO update。Early update指的是一旦最优的分割无法实现,就立即更新。Early update的一个缺点是,搜索可能永远不会到达训练样本的末尾,这意味着数据的其余部分是“浪费”的。而LaSO update在每次更新后都在相同的实例上继续进行正确的假设(将正确的分词序列的对应前缀插入实例中)。
\[
\operatorname{COMP}\left(c_{1} . . c_{l}\right)=\tanh \left(\mathbf{W}_{l}^{c}\left[\mathbf{r}_{1} \odot \mathbf{c}_{1} ; \ldots ; \mathbf{r}_{l} \odot \mathbf{c}_{l}\right]+\mathbf{b}_{l}^{c}\right)
\] \[
\left[\mathbf{r}_{1} ; \ldots ; \mathbf{r}_{l}\right]=\operatorname{sigmoid}\left(\mathbf{W}_{l}^{r}\left[\mathbf{c}_{1} ; \ldots ; \mathbf{c}_{l}\right]+\mathbf{b}_{l}^{r}\right)
\] 作者讲gate mechanism进行了简化,使得模型训练更加快速。另外,原模型中的Beam Search也改为了贪心算法,采用了两种训练方法:Early update、LaSO update。Early update指的是一旦最优的分割无法实现,就立即更新。Early update的一个缺点是,搜索可能永远不会到达训练样本的末尾,这意味着数据的其余部分是“浪费”的。而LaSO update在每次更新后都在相同的实例上继续进行正确的假设(将正确的分词序列的对应前缀插入实例中)。
Transition-Based Neural Word Segmentation
 上图为Transition-Based分词方法,它使用Transition system递增地去分词。Buffer部分用于存储句子已经分词的部分,未分词的在Queue中。action包括SEP-separate和APP-append,分别指分割和把字符pop到Buffer中。模型分词的过程就是寻找一个action序列的过程。
上图为Transition-Based分词方法,它使用Transition system递增地去分词。Buffer部分用于存储句子已经分词的部分,未分词的在Queue中。action包括SEP-separate和APP-append,分别指分割和把字符pop到Buffer中。模型分词的过程就是寻找一个action序列的过程。
这个框架中的基本的特征包含三方面的信息。第一个信息是序列q中第一个字符和buffer中的最后一个字符用来分别给SEP和APP动作来打分。第二个信息是通过已经被识别的词来指导SEP。第三个信息是已识别的词的相关信息,比如它们的长度,这个词中的第一个字符或是最后一个字符可以作为额外的特征。从图中可以看到三个RNN分别编码word sequence、character sequence以及action sequence信息。而论文的作者则在这一框架的基础上用LSTM替换了原有的RNN。
Pre-train model
BERT诞生后横扫各大NLP任务的榜单,中文分词自然也逃不了它的魔爪。BERT作为特征提取器,基于BERT的分词模型事实上大部分属于基于字符的分词技术。而基于BERT的分词模型的关注点则主要包括:在 模型中融合自定义词典、外部知识(领域知识);如何大模型蒸馏成一个小的模型来提高分词性能;如何通过不同粒度标准的分词预料联合预训练,让分词能够通过某些简单的控制能够适应不用的分词场景。
部分相关论文:
Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter
Pre-training with Meta Learning for Chinese Word Segmentation
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations (这个模型缩写就离谱)

写在最后
 目前在几个公开数据集上分词模型的分词准确率都达到了97%以上。作为一个对于中文NLP来说非常重要的任务,中文分词可以说基于属于已经解决的任务,毕竟分词本就很难有绝对统一的标准。而就目前来说,相较于刷新榜单,或许更重要的是寻找更好解决OOV问题的方法(毕竟每段时间都有大量新词涌现)以及研发速度更快、体量更小的模型。
目前在几个公开数据集上分词模型的分词准确率都达到了97%以上。作为一个对于中文NLP来说非常重要的任务,中文分词可以说基于属于已经解决的任务,毕竟分词本就很难有绝对统一的标准。而就目前来说,相较于刷新榜单,或许更重要的是寻找更好解决OOV问题的方法(毕竟每段时间都有大量新词涌现)以及研发速度更快、体量更小的模型。
