背景
随着深度学习技术的发展,基于深度神经网络的中文分词模型也不断涌现,这类分词技术大致上可以分为两类,其中一类基于字符的中文分词方法将分词看作字符的标注问题。根据字在词中的位置,分别给每个中文字符打上B、M、E、S的标签,将分词转化为字的标签预测。
深度神经网络
Deep Learning for Chinese Word Segmentation and POS Tagging
 这篇论文是早期使用神经网络来做中文分词和词性标注的联合任务。对比机器学习模型,早期的神经网络致力于改善手工设计或选择特征这一问题,借助深层网络自动获取任务相关的字符特征。作为统计语言模型,这种方法利用大规模非标注数据来改善中文字符的内在表示,然后使用这些改善后的表示来提高有监督的分词模型和词性标注模型的性能。
这篇论文是早期使用神经网络来做中文分词和词性标注的联合任务。对比机器学习模型,早期的神经网络致力于改善手工设计或选择特征这一问题,借助深层网络自动获取任务相关的字符特征。作为统计语言模型,这种方法利用大规模非标注数据来改善中文字符的内在表示,然后使用这些改善后的表示来提高有监督的分词模型和词性标注模型的性能。
对于输入句子中的每一个字,神经网络架构将为其可能的每一个TAG进行评分,为了解决不同句子对应的字序列长短不一的问题,本文中采用的是窗口方法。窗口方法假定一个字的tag主要依赖于与其相邻的字。具体而言,如上图所示,首先对输入的句子中的每个字查词典:通过lookup层得到窗口中每个字的字向量。之后将每个窗口长度的字向量首尾相连得到一个新的特征。接下来经过3层基础的神经网络。神经网络的输出是一个包含每个字可能标签的得分的矩阵。最后使用Viterbi算法进行动态规划完成标注的推断。
LSTM
Long Short-Term Memory Neural Networks for Chinese Word Segmentation
基于DNN的分词模型所能关注的是每个字符的窗口内邻近字符的特征,而LSTM则能解决句子内字符的长期依存关系问题。举个简单的例子:
冬天,能穿/多少/穿/多少,夏天,能穿/多/少/穿/多/少。
此时这个“多少”的分词就需要根据句子开头的“冬天”和“夏天”来确定。 
因此模型在原有深度学习分词的框架下,将传统的3层神经网络改为LSTM,借助输入输出门和遗忘门来传递上文信息。
\[ \begin{aligned} \mathbf{i}^{(t)} &=\sigma\left(\mathbf{W}_{i x} \mathbf{x}^{(t)}+\mathbf{W}_{i h} \mathbf{h}^{(t-1)}+\mathbf{W}_{i c} \mathbf{c}^{(t-1)}\right) \\ \mathbf{f}^{(t)} &=\sigma\left(\mathbf{W}_{f x} \mathbf{x}^{(t)}+\mathbf{W}_{f h} \mathbf{h}^{(t-1)}+\mathbf{W}_{f c} \mathbf{c}^{(t-1)}\right) \\ \mathbf{c}^{(t)} &=\mathbf{f}^{(t)} \odot \mathbf{c}^{(t-1)}+\mathbf{i}^{(t)} \odot \phi\left(\mathbf{W}_{c x} \mathbf{x}^{(t)}+\mathbf{W}_{c h} \mathbf{h}^{(t-1)}\right) \\ \mathbf{o}^{(t)} &=\sigma\left(\mathbf{W}_{o x} \mathbf{x}^{(t)}+\mathbf{W}_{o h} \mathbf{h}^{(t-1)}+\mathbf{W}_{o c} \mathbf{c}^{(t)}\right) \\ \mathbf{h}^{(t)} &=\mathbf{o}^{(t)} \odot \phi\left(\mathbf{c}^{(t)}\right) \end{aligned} \]
但是在这个模型中,我们可以发现一个明显的问题,模型只能关注字符上距离的上文内容而无法获取下文信息用于辅助分词。针对这一问题,就有了Bi-LSTM,用双向LSTM来利用上下文信息。
Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation
这篇论文使用了双向LSTM,即两个并行的LSTM分别来从左到右和从右到左来提取长距离字符特征。另外,模型输出为softmax之后的概率向量,比起之前的工作省略了viterbi推断的过程,变为end-end的模型。 
Multi-Criteria Learning
Adversarial Multi-Criteria Learning for Chinese Word Segmentation
不同的语料库有不同的分词标准,这篇文章的作者试图借助对多个不同标准的分词语料进行模型训练,提取中分词方法中最具普适性的部分。具体而言,模型借助Multi-criteria learning来获取多个准则的共享权重和独有权重,另一方面,通过鉴别器的对抗性训练来更好的实现这一过程,使得多准则的共享特性被更好地提取。
整体模型架构是建立在Bi—LSTM模型下,而针对具体的特征提取网络,作者针对多准则学习设计了三种网络结构,如下图所示 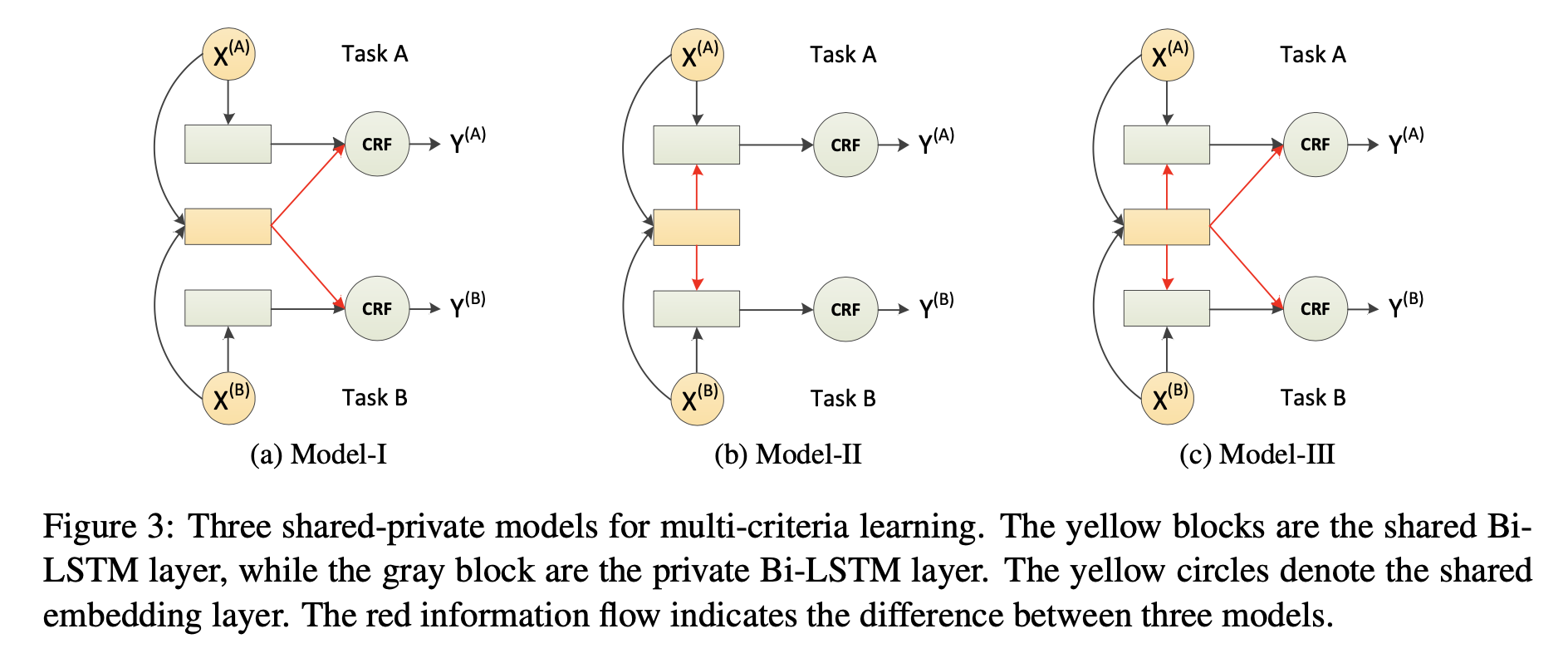 其中黄色为共享LSTM层,灰色为私有LSTM层,\(\Theta^{m}, \Theta^{s}\)分别代表他们的参数。每种模型都有两种准则进行训练,训练的目标函数是所有语料库上数据的条件似然。
其中黄色为共享LSTM层,灰色为私有LSTM层,\(\Theta^{m}, \Theta^{s}\)分别代表他们的参数。每种模型都有两种准则进行训练,训练的目标函数是所有语料库上数据的条件似然。
\[ \mathcal{J}_{s e g}\left(\Theta^{m}, \Theta^{s}\right)=\sum_{m=1}^{M} \sum_{i=1}^{N_{m}} \log p\left(Y_{i}^{(m)} \mid X_{i}^{(m)} ; \Theta^{m}, \Theta^{s}\right) \]
而为了确保共享层中没有参杂特定准则的私有信息,模型引入了一个鉴别器进行对抗训练。 ") 判别器的任务是预测某一特征向量来源于 多准则语料中的哪一个。假如判别器能够准确预测每一个共享特征向量的来源语料,则说明这些共享特征中混入了太多私有信息。而共享LSTM层的目标则是让判别器无法鉴别输出的特征向量来源于哪个预料。模型通过令这两者进行对抗性训练,使得共享层能够提取出多个准则中最本质的分词特性。
判别器的任务是预测某一特征向量来源于 多准则语料中的哪一个。假如判别器能够准确预测每一个共享特征向量的来源语料,则说明这些共享特征中混入了太多私有信息。而共享LSTM层的目标则是让判别器无法鉴别输出的特征向量来源于哪个预料。模型通过令这两者进行对抗性训练,使得共享层能够提取出多个准则中最本质的分词特性。
Joint CWS and POS Tagging
A Feature-Enriched Neural Model for Joint Chinese Word Segmentation and Part-of-Speech Tagging
本文的模型将Chinese word segmentation与part-of-speech (POS) tagging两个任务进行联合训练,因为其本质上都属于character based sequence labeling task。而论文作者的改进之处在于一个精心设计的特征提取网络 Feature-Enriched Neural Model。

抛开原有的框架,这个模型增加了2个模块——Convolutional layer; Highway layer。
首先,卷积层用来对标传统方法中的手工字符特征部分。作者认为简单的神经模型只是将字符的局部信息嵌入并连接起来,不能模拟传统机器学习模型中精心设计的特征。为了像传统的基于特征的模型那样更好地建模复杂的字符特征,作者使用卷积层对每个特征分别建模不同的n-gram特征并串联,然后我们k-max池化层来选择最显著的部分。
\(\hat{\mathbf{z}}_{i}^{q}\)代表Q-gram特征 (uni-gram, bi-gram, ... ,),而\(\mathbf{W}_{c o v}^{q} \in \mathbf{R}^{q d \times l_{q}}\) 代表convolutional filter
\[ \hat{\mathbf{z}}_{i}^{q}=\tanh \left(\mathbf{W}_{\operatorname{cov}}^{q}{ }^{\top} \times \mathbf{x}_{i-\left|\frac{q-1}{2}\right|: i+\left[\frac{q-1}{2}\right]}^{+}+\mathbf{b}\right), i \in[1, n] \]
而后分别进行concatenation、k-max pooling操作 \[ \mathbf{z}_{i}=\oplus_{q=1}^{Q} \hat{\mathbf{z}}_{i} \]
此时,输入的原始句子就会被表示为\(\hat{\mathbf{X}} \in \mathbf{R}^{n \times d}=\) \(\left[\hat{\mathbf{x}}_{1}, \hat{\mathbf{x}}_{2}, \ldots, \hat{\mathbf{x}}_{n}\right]^{\top}\), 其中\(\hat{\mathbf{x}}_{i}\)为:
\[ {\hat{\mathbf{x}}}_{i}=k \max \mathbf{z}_{i}, k=d . \]
Highway layer则用来增加结构的深度,来模拟更复杂的组合特征。此外,highway加快了模型的收敛速度,缓解了梯度消失的问题。(这部分是参考Highway Netowrk(2015)的模型)
我们讲卷积后的句子表示为 \(\hat{\mathbf{X}}=\operatorname{Cov}(\mathbf{X})\),而其经过Highway layer后会得到 \[ \hat{\mathbf{X}}=\operatorname{Cov}(\mathbf{X}) \odot T(\mathbf{X})+\mathbf{X} \odot C(\mathbf{X}) \] 其中\(\odot\)代表按元素乘运算,\(C(\cdot)=1-T(\cdot)\),而\(T(\cdot)\)则可以写为: \[ T(\mathbf{X})=\sigma\left(\mathbf{W}_{T}{ }^{\boldsymbol{\top}} \times \mathbf{X}+\mathbf{b}_{T}\right) \] 其中\(\mathbf{W}_{T} \in \mathbf{R}^{d \times d}\)、\(\mathbf{b}_{T} \in \mathbf{R}^{d}\)是可训练参数,\(\sigma\)是sigmoid函数。
而接下来就将结果输入到BLSTM中,并借助CRF作为Decoder得到最终的结果。
