link: https://aclanthology.org/2020.acl-main.734/
代码
背景
在中文自然语言处理中,分词是一个非常重要的任务。中文分词技术存在两个主要难点:未登录词(OOV)和歧义消除问题。本文属于基于字符的分词模型,主要思想是利用键值记忆网络来辅助分词,使分词的语义更加完整。
模型框架
模型将中文分词作为序列标注问题,核心思想是在传统NER模型的Encoder-Decoder之间添加一个memory network,Encoder可以用BERT或BiLSTM等将汉字序列表示为向量,Decoder可以是Softmax或者CRF。模型总体可以表示为: \[ \widehat{\mathcal{Y}}=\underset{\mathcal{Y} \in \mathcal{T}^{l}}{\arg \max } p(\mathcal{Y} \mid \mathcal{X}, \mathcal{M}(\mathcal{X}, \mathcal{N})) \] 其中\(\mathcal{T}\)表示句子中所有分词结果的标签集;\(l\)是句子长度。\(\widehat{\mathcal{Y}}\)为该模型得到的最佳结果,\(\mathcal{N}\)为构造的词典,\(\mathcal{X}\)为输入句,\(\mathcal{M}\)为本文提出的模型。

词典构建
本文构建的词典实际上是一个N-gram词典,它包含了一个句子中所有可能的N-gram。模型利用前人的模型——Accessor Variety,找出输入句子中所有可能的n-gram集合。根据上图给出的例子,所构建的词典如图底部所示。
Wordhood Memory Networks
这部分是本文最重要的部分。作者利用键值记忆网络将字符n-gram与它们的词伙(wordhood)度量相结合。其中key-value分别对应n-grams和wordhood。具体可以分成两个步骤:
Key Addressing
首先对该句子构建Lexicon,对每一个汉字\(x_i\) ,有可能存在很多包含该汉字的n-gram。比如上面的句子中的第四个字"民"构建Lexicon,可以表示为: \[ K_{4}=[\text {"民"," 居民", " 民生", " 居民生活"] } \]然后将这些n-gram进行key embeding后\(e_{i, j}^{k}\)再与Encoder传来的\(h_i\) 相乘之后做softmax得到一个概率分布。概率大小就表明了相关程度: \[ p_{i, j}=\frac{\exp \left(h_{i} \cdot e_{i, j}^{k}\right)}{\sum_{j=1}^{m_{i}} \exp \left(h_{i} \cdot e_{i, j}^{k}\right)} \]Value Reading
先将每个\(k_i\)映射到一个标注值V上,因为每个字在不同的n-gram中的位置不同,所以需要映射的值也不同,这里使用B I E S标记法:(B:begin ,I:inside,E:end,S:single),还是上面的例子,对应Key Addressing时的\(K_4\),得到的value集合为: \[ V_{4}=\left[V_{S}, V_{E}, V_{B}, V_{I}\right] \]而后将每个value进行embedding得到\(e_{i, j}^{v}\),与上一步得到的概率进行相乘累加,得到的结果再与Encoder传入的\(h_i\)结合得到最终输出的vector \(a_i\)。 \[ O_{i}=\sum_{j=1}^{m_{i}} p_{i, j} e_{i, j}^{v} \]
接下来就可以和正常的NER模型一样使用一个decoder(softmax、crf等等) 得到一个句子的分词结果了。
实验
1.消融实验。作者使用了5个基准数据集,分别是CTB6、MSR、PKU、AS和CITYU。将Wordhood Memory Networks加入到目前主流的分词模型中进行比较,实验结果表明,虽然原始的模型有很好的性能,但加入Wordhood Memory Networks后仍有很大的改进
2.在五个基准数据集的测试集上,WMSEG和以前的SOTA模型的性能比较。经过实验比较,本文提出的模型在中文分词方面达到了SOTA水平,OOV的召回率有了很大的提高。

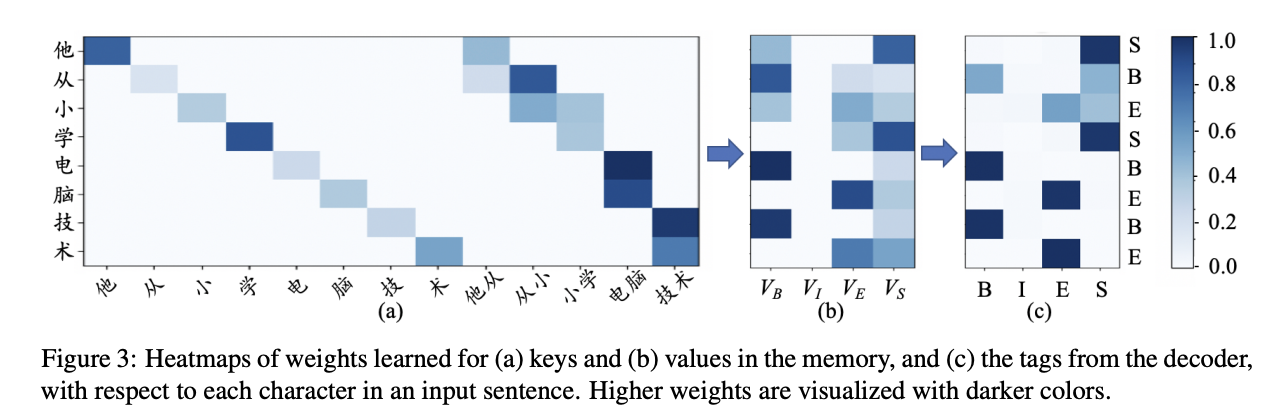
例子分析
作者用“他从小学习电脑技术”这一句子的分词结果进行可视化分析,发现通过Wordhood Memory Networks对n-gram语义的捕捉,给了“从小”一个较高的权重、"小学"一个较低的权重,得到了正确的分词结果。