ICML2019的论文,作者为Stanford的phd。
先说几句
看到摘要
Our model parameterizes variational autoencoders (VAE) with graph neural networks, and uses a novel iterative graph refinement strategy inspired by low-rank approximations for decoding.
基本可以确定模型相当于variational graph autoencoders,但是VGAE这名字已经被人抢了XD。不过对比VGAE,它用了更优的Decoder。另一方面,作者给出了图神经网络中message passing与平均场变分推理之间的理论联系。
Graphite
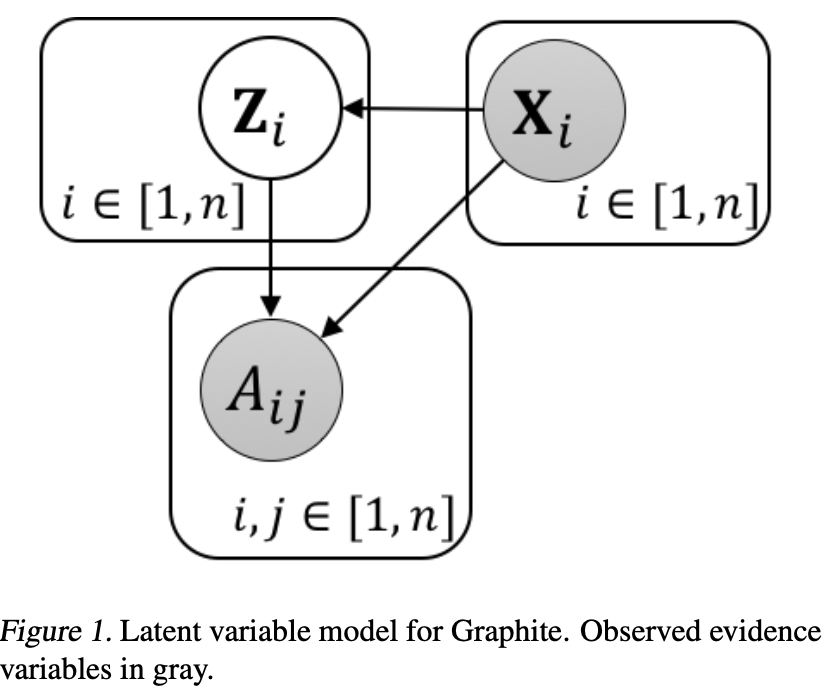 模型的整体架构与VGAE相似。其中Encoder为 \[
\boldsymbol{\mu}, \boldsymbol{\sigma}=\mathrm{GNN}_{\phi}(\mathbf{A}, \mathbf{X})
\] 接下来我们重点来看模型的Decoder。在VGAE中,Decoder是节点隐变量的内积,而Graphite提出了reverse message passing作为Decoder。 \[
\begin{aligned}
\widehat{\mathbf{A}} &=\frac{\mathbf{Z Z}^{T}}{\|\mathbf{Z}\|^{2}}+\mathbf{1 1}^{T} \\
\mathbf{Z}^{*} &=\operatorname{GNN}_{\theta}(\widehat{\mathbf{A}},[\mathbf{Z} \mid \mathbf{X}])
\end{aligned}
\] 模型不断迭代上述两个步骤,也就是reverse message passing。 首先第一步借助隐变量矩阵的内积构建一个邻接矩阵(图)\(\widehat{\mathbf{A}} \in \mathbb{R}^{n \times n}\),加上单位矩阵保证非负。第二步中先将Z和X进行级联,而后与构建的图输入到GNN中。通过不断的重复来更新\(Z^*\),最后使用最终的Z进行内积得到生成的邻接矩阵\(\hat A\)。另外,由于图学习通常是在大规模图上操作,在迭代过程中的求内积可以借助GNN这一步中的矩阵乘法来降低复杂度。
模型的整体架构与VGAE相似。其中Encoder为 \[
\boldsymbol{\mu}, \boldsymbol{\sigma}=\mathrm{GNN}_{\phi}(\mathbf{A}, \mathbf{X})
\] 接下来我们重点来看模型的Decoder。在VGAE中,Decoder是节点隐变量的内积,而Graphite提出了reverse message passing作为Decoder。 \[
\begin{aligned}
\widehat{\mathbf{A}} &=\frac{\mathbf{Z Z}^{T}}{\|\mathbf{Z}\|^{2}}+\mathbf{1 1}^{T} \\
\mathbf{Z}^{*} &=\operatorname{GNN}_{\theta}(\widehat{\mathbf{A}},[\mathbf{Z} \mid \mathbf{X}])
\end{aligned}
\] 模型不断迭代上述两个步骤,也就是reverse message passing。 首先第一步借助隐变量矩阵的内积构建一个邻接矩阵(图)\(\widehat{\mathbf{A}} \in \mathbb{R}^{n \times n}\),加上单位矩阵保证非负。第二步中先将Z和X进行级联,而后与构建的图输入到GNN中。通过不断的重复来更新\(Z^*\),最后使用最终的Z进行内积得到生成的邻接矩阵\(\hat A\)。另外,由于图学习通常是在大规模图上操作,在迭代过程中的求内积可以借助GNN这一步中的矩阵乘法来降低复杂度。

Theoretical Analysis
这一部分是作者对图神经网络的message passing与近似推断的关系。
首先我们定义kennel,\(K: \mathcal{Z} \times \mathcal{Z} \rightarrow \mathbb{R}\);映射函数 \(T_{\psi}: \mathcal{P} \rightarrow \mathcal{H}\) 其中\(\mathcal{P}\)定义了\(\mathcal{Z}\)上所有分布的空间。因此可以定义对变量Z的分布的映射,或者成为kernel embedding: \[
T_{\psi}(p):=\mathbb{E}_{Z \sim p}[\psi(Z)]
\] 我们令这种映射\(\psi\)是单射的,即对于任意两个分布\(p_1,p_2\),当\(p_{1} \neq p_{2}\),有\(T_{\psi}\left(p_{1}\right) \neq T_{\psi}\left(p_{2}\right)\)。接下来我们定义 函数\(\mathcal{O}: \mathcal{P} \rightarrow \mathbb{R}^{d}, d \in \mathbb{N}\),对于每个\(T_{\psi}\)和\(\mathcal{O}\),都存在\(\tilde{\mathcal{O}}_{\psi}: \mathcal{H} \rightarrow \mathbb{R}^{d}\)使得: \[
\mathcal{O}(p)=\tilde{\mathcal{O}}_{\psi}\left(T_{\psi}(p)\right) \quad \forall p \in \mathcal{P}.
\]
在GNN中,我们假设\(X\)和\(A\)都是观测到且在隐变量的条件概率分布中的相互独立的。也就是说我们期望的图是满足,对于\(Z\)上的条件分布,当\(A\)、\(X\)和由边集\(E\)确定的节点i的邻接潜变量时,任意单个\(Z_i\)与所有其他\(Z_j\)都是独立的。这句话非常抽象,可以从下图来理解。 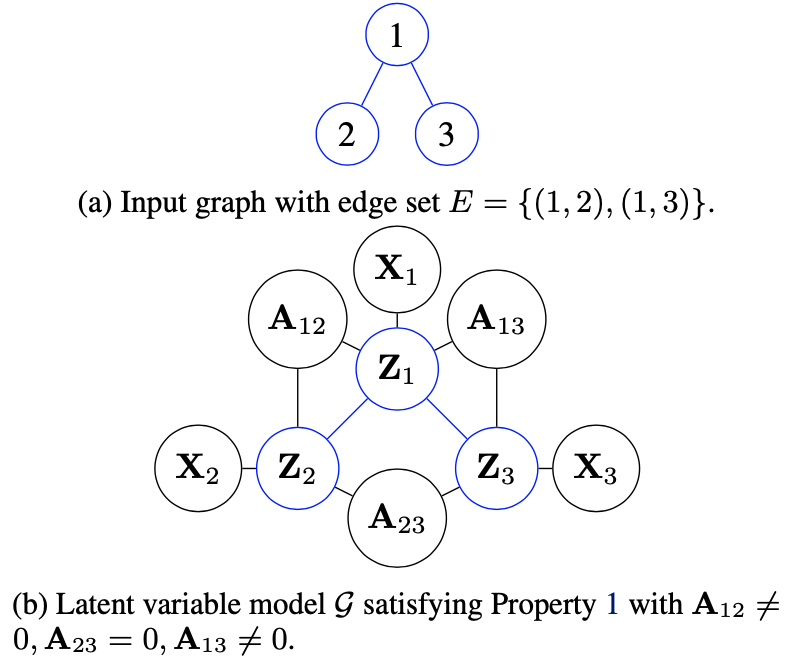
当图\(G\)满足这一条件是,我们就可以用平均场理论 (mean-feild) \[ r\left(\mathbf{Z}_{1}, \cdots, \mathbf{Z}_{n} \mid \mathbf{A}, \mathbf{X}\right) \approx \prod_{i=1}^{n} q_{\phi_{i}}\left(\mathbf{Z}_{i} \mid \mathbf{A}, \mathbf{X}\right) \] 其中\(\phi_{i}\) 代表第i个变分边界的参数。而后我们用真实的条件概率分布与上式的KL散度来优化这些参数: \[ \min _{\phi_{1}, \cdots, \phi_{n}} \mathrm{KL}\left(\prod_{i=1}^{n} q_{\phi_{i}}\left(\mathbf{Z}_{i} \mid \mathbf{A}, \mathbf{X}\right) \| r\left(\mathbf{Z}_{1}, \cdots, \mathbf{Z}_{n} \mid \mathbf{A}, \mathbf{X}\right)\right) \]
而最优的变分边界满足以下形式(证明见论文) \[ q_{\phi_{i}}\left(\mathbf{Z}_{i} \mid \mathbf{A}, \mathbf{X}\right)=\mathcal{O}_{\mathcal{G}}^{M F}\left(\mathbf{Z}_{i},\left\{q_{\phi_{j}}\right\}_{j \in \mathcal{N}(i)}\right) \] 其中\(\mathcal{N}(i)\)为\(\mathbf{Z}_{i}\)的邻节点。\(\mathcal{O}\)是一个由不动点方程确定的函数,它依赖于图自身的性质。这一形式意味着最优的\(q_{\phi_{i}}\)的参数只与i的邻节点的q_{}有关。这就意味着平均场近似推断的迭代算法是在图上执行信息传递,直到收敛: \[ q_{\phi_{i}}^{(l)}\left(\mathbf{Z}_{i} \mid \mathbf{A}, \mathbf{X}\right)=\mathcal{O}_{\mathcal{G}}^{M F}\left(\mathbf{Z}_{i},\left\{q_{\phi_{j}}^{(l-1)}\right\}_{j \in \mathcal{N}(i)}\right) . \]
令\(\boldsymbol{\mu}_{i}=\mathbb{E}_{\mathbf{Z}_{i} \sim q_{\phi_{i}}}\left[\psi\left(\mathbf{Z}_{i}\right)\right]\),根据上文提到的结论,我们就可以绕开 具体的\(\mathcal{O}\),将其变为 \[ \boldsymbol{\mu}_{i}^{(l)}=\tilde{O}_{\psi, \mathcal{G}}^{M F}\left(\left\{\boldsymbol{\mu}_{j}^{(l-1)}\right\}_{j \in \mathcal{N}(i)}\right) \] 将上式在0处做一阶泰勒展开,有 \[ \mu_{i}^{(l)} \approx \tilde{O}_{\psi, \mathcal{G}}(\mathbf{0})+\mathbf{N}_{i}^{(l-1)} \cdot \nabla \tilde{O}_{\psi, \mathcal{G}}(\mathbf{0}) \] 这式从形式上就与message passing机制非常类似。 \[ H_{i}^{(l)}=\eta_{l}\left(B_{l, i}+\sum_{f \in \mathcal{F}_{l}} f\left(\mathbf{A}_{i}\right) \mathbf{H}^{(l-1)} W_{l}\right) \] 由于在看推导过程时把一些分量的维度等忽略了,因此最后一步的具体细节直接在这里贴原文。

