本文来自Thomas Kipf的博士论文,其论文其他内容包括GCN、relational GCN、compositional imitation learning and execution等。
对于图\(G=(V,E)\),有\(N=|V|\),邻接矩阵\(A\)为\(N \times N\),用\(s\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)\)来度量两个节点ij的相似度,其中\({z}_{i}, {z}_{j}\)为节点的embedding
GAE

Graph Auto-Encoder同样采用encoder-decoder架构,其中scoring function \(s\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)\)作为decoder,其根据节点嵌入来重构邻接矩阵;Encoder的输入为图的邻接矩阵\(A\)以及节点的特征向量\(\left\{\mathbf{x}_{i}\right\}_{i \in \mathcal{V}}\),输出为node representations \(\mathbf{Z}_{i}\)。
Encoder
GAE的Encoder借助GNN来处理节点的初始化向量和图的结构信息,从而得到节点的表示。比如使用GCN作为Encoder时,有: \[ \mathbf{Z}=\operatorname{GCN}(\mathbf{X}, \mathbf{A})=\widehat{\mathbf{A}} \operatorname{ReLU}\left(\widehat{\mathbf{A}} \mathbf{X} \mathbf{W}_{0}\right) \mathbf{W}_{1} \] 除了用GNN作为encoder之外,还有其他的embedding方法,比如最简单的shallow embedding直接根据节点的编号,以及DeepWalk、node2vec等方法。Decoder
Decoder用来根据\(Z\)重建邻接矩阵 \[ \mathbf{A}^{\prime}=l\left(\mathbf{Z Z}^{\top}\right) \] 其中\(l(.)\)是logistic sigmoid function,也就是说\(A_{i, j}^{\prime}=l\left(s\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)\right)\)
不过在图表示学习一书中给出了多种decoder 
- Training
使用交叉熵进行训练 \[ \mathcal{L}=-\frac{1}{N^{2}} \sum_{i=1}^{N} \sum_{j=1}^{N} A_{i, j} \log l\left(s\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)\right)+\left(1-A_{i, j}\right) \log \left(1-l\left(s\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)\right)\right) \]
VAE

在介绍变分图自编码器 (VGAE)之前,我们先简单介绍一下变分自编码器Variational Auto-encoders。[Auto-Encoding Variational Bayes]
 上图中的实线就代表了生成模型\(p_{\boldsymbol{\theta}}(\mathbf{z}) p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z})\),也就是根据隐变量z生成目标数据。而这一生成模型中,我们需要用\(q_{\phi}(\mathbf{z} \mid \mathbf{x})\)来拟合无法得到的后验分布\(p_{\boldsymbol{\theta}}(\mathbf{z} \mid \mathbf{x})\)。而这里就涉及到变分推断VI的内容。
上图中的实线就代表了生成模型\(p_{\boldsymbol{\theta}}(\mathbf{z}) p_{\boldsymbol{\theta}}(\mathbf{x} \mid \mathbf{z})\),也就是根据隐变量z生成目标数据。而这一生成模型中,我们需要用\(q_{\phi}(\mathbf{z} \mid \mathbf{x})\)来拟合无法得到的后验分布\(p_{\boldsymbol{\theta}}(\mathbf{z} \mid \mathbf{x})\)。而这里就涉及到变分推断VI的内容。
接下来我们具体展开来说。
给定一个真实样本 \(x_{k}\), 我们假设存在一个后验分布\(p\left(z \mid x_{k}\right)\) 并假设这个分布是正态分布。后续我们要训练一个生成器\(x=g(z)\), 使其能从分布\(p\left(z \mid x_{k}\right)\) 采样出来的一个 \(\hat x_{k}\) 还原为\(x_{k}\)。
对于正态分布的两个参数:均值 \(\mu\) 和方差 \(\sigma^{2}\),我们用神经网络进行拟合\(\mu_{k}=f_{1}\left(x_{k}\right), \log \sigma_{k}^{2}=f_{2}\left(x_{k}\right)\)。再借助重参数技巧从\(z_k\)的分布中采样得到\(z_k\)。(对于重参数技巧,就是使采样这一步骤变为可导的一种方法)。
由于VAE最开始假设了隐变量服从正态分布,这就需要神经网络拟合的分布\(p\left(z \mid x_{k}\right)\)向标准正态分布看起,因为 \[ p(z)=\sum_{x} p(z \mid x) p(x)=\sum_{x} \mathcal{N}(0, I) p(x)=\mathcal{N}(0, I) \sum_{x} p(x)=\mathcal{N}(0, I) \] 使分布与标准正态看齐这一过程借助在loss增加一个额外的loss(生成分布与标准正态分布的KL散度)来实现 \[ \mathcal{L}_{\mu, \sigma^{2}}=\frac{1}{2} \sum_{i=1}^{d}\left(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right) \]
上述的过程介绍从Auto-Encoder的角度来介绍VAE,事实上如果阅读原论文会发现这种介绍VAE的思路是很令人费解的。回到最基础的贝叶斯学习,我们需要\(q_{\phi}\left(\mathrm{z} \mid \mathrm{x}^{(i)}\right)\) 去逼近真实的后验概率 \(p_{\theta}\left(\mathrm{z} \mid \mathrm{x}^{(i)}\right)\),很自然的我们选择用KL散度作为loss,而后经过变分推断的推到转换为优化变分下界 \[ \tilde{\mathcal{L}}\left(\theta, \phi ; \mathrm{x}^{(i)}\right)=\frac{1}{L} \sum_{l=1}^{L}\left[\log p_{\theta}\left(\mathrm{x}^{(i)}, \mathrm{z}^{(i, l)}\right)-\log q_{\phi}\left(\mathrm{z}^{(i, l)} \mid \mathrm{x}^{(i)}\right)\right] \] 其中, \(\mathrm{z}^{(i, l)}=g_{\phi}\left(\epsilon^{(i, l)}, \mathrm{x}^{(i)}\right), \quad \epsilon^{(i, l)} \sim p(\epsilon)\) 。
而VAE正是给定上述结果中\(\epsilon, p_{\theta}(\mathrm{x} \mid \mathrm{z}), q_{\phi}(\mathrm{z} \mid \mathrm{x}), p_{\theta}(\mathrm{z})\) 分布具体形式(正态分布)后的特例。
VGAE

对于变分图自编码器,简单来看就是输入变为节点特征和邻接矩阵,输出为生成的邻接矩阵。
\(p_{\theta}(\mathbf{A} \mid \mathbf{X})\)为节点特征\(X\)与邻接矩阵A的条件概率分布 \[ p_{\boldsymbol{\theta}}(\mathbf{A} \mid \mathbf{X})=\int p_{\boldsymbol{\theta}}(\mathbf{A} \mid \mathbf{Z}, \mathbf{X}) p(\mathbf{Z} \mid \mathbf{X}) d \mathbf{Z} \] 其中隐变量先验分布独立于特征向量X,只和节点自身有关\(p(\mathbf{Z} \mid \mathbf{X})=\prod_{i=1}^{N} p\left(\mathbf{z}_{i}\right)\)。更具体的说,我们令\(p\left(\mathbf{z}_{i}\right)=\mathcal{N}\left(\mathbf{z}_{i} ; \mathbf{0}, \mathbf{I}\right)\)。我们的目标是得到最优的参数\(\theta\)。
根据变分推断的框架,我们引入inference model: \[ q_{\phi}(\mathbf{Z} \mid \mathbf{X}, \mathbf{A})=\prod_{i=1}^{N} q_{\phi}\left(\mathbf{z}_{i} \mid \mathbf{X}, \mathbf{A}\right) \] 其中 \(q_{\phi}\left(\mathbf{z}_{i} \mid \mathbf{X}, \mathbf{A}\right)=\mathcal{N}\left(\mathbf{z}_{i} ; \boldsymbol{\mu}_{i}, \operatorname{diag}\left(\sigma_{i}^{2}\right)\right)\)
具体模型中,我们用两个GCN作为学习inference model的参数: \[ \mu_{i}=\left[\mathrm{GCN}^{(1)}(\mathbf{X}, \mathbf{A})\right]_{i} \] \[ \log \sigma_{i}=\left[\mathrm{GCN}^{(2)}(\mathbf{X}, \mathbf{A})\right]_{i} \]
接下来的generative model,我们假设它与初始输入的节点特征无关,只与隐变量有关, \[ p_{\boldsymbol{\theta}}(\mathbf{A} \mid \mathbf{Z}, \mathbf{X})=\prod_{i=1}^{N} \prod_{j=1}^{N} p_{\boldsymbol{\theta}}\left(A_{i, j} \mid \mathbf{z}_{i}, \mathbf{z}_{j}\right) \]
模型所要优化的KL散度与变分推断的过程相似,可以变为优化 \[ \operatorname{ELBO}=\mathbb{E}_{q_{\phi}(\mathbf{Z} \mid \mathbf{X}, \mathbf{A})}\left[\log p_{\theta}(\mathbf{A} \mid \mathbf{Z}, \mathbf{X})\right]-\operatorname{KL}\left[q_{\phi}(\mathbf{Z} \mid \mathbf{X}, \mathbf{A}) \| p(\mathbf{Z})\right]. \]
我们可以将上述过程写的通俗一点,其中编码过程为: \[ q\left(z_{i} \mid X, A\right)=N\left(z_{i} \mid \mu_{i}, \operatorname{diag}\left(\sigma_{i}^{2}\right)\right). \] 解码(以内积为例)的过程为: \[ p\left(A_{i j}=1 \mid z_{i}, z_{j}\right)=\sigma\left(z_{i}^{T} z_{j}\right)_{\circ} \] 损失函数为: \[ L=E_{q(Z \mid X, A)}[\log p(A \mid Z)]-K L[q(Z \mid X, A) \| p(Z)] \]
作者在边预测任务上测试了VGAE的表现。不过,在Decoder时不考虑节点的特征\(X\)仅仅是为了将模型简化,作者发现这不影响link prediction的准确率。 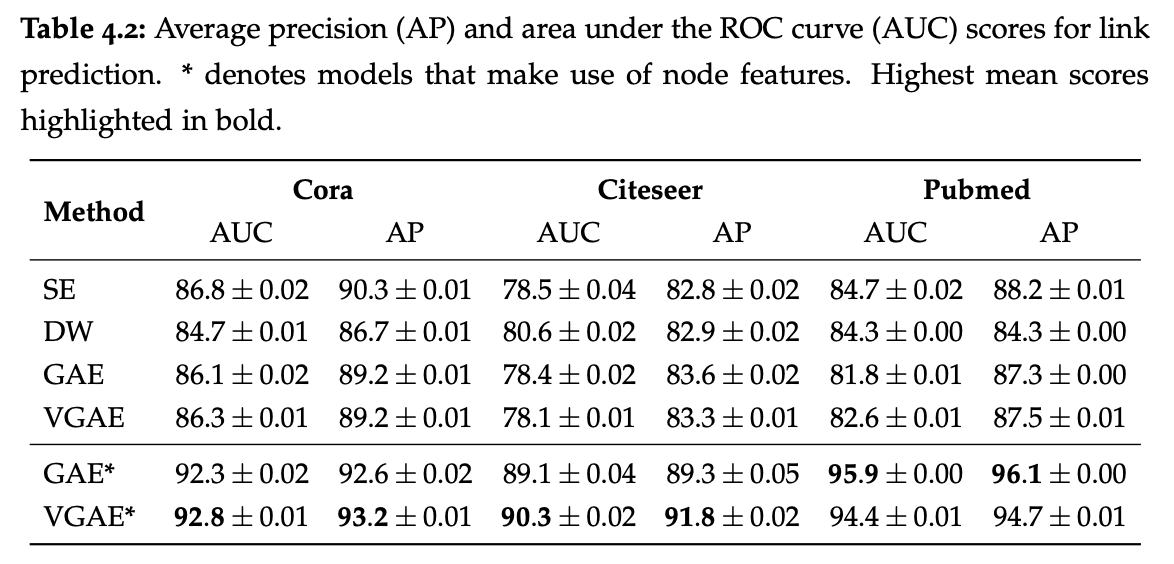
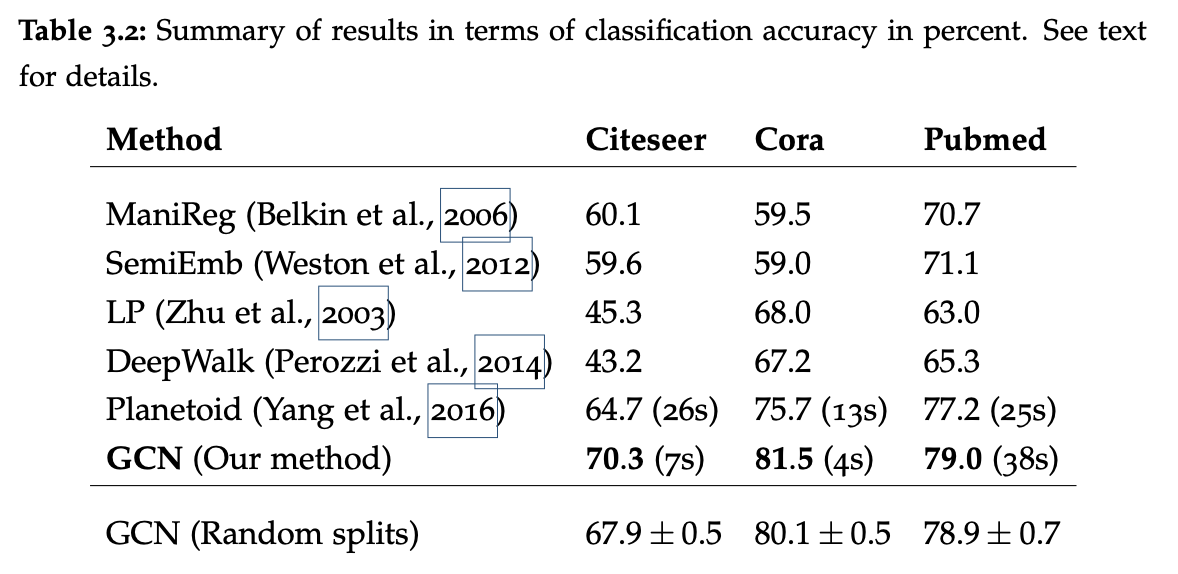
值得推敲的是,在论文的前面有关于图卷积GCN在这几个数据集上的表现。而作者却没有用统一的评价指标(精度和准确率)来对比这两个模型的表现。