截止2021年初,关于现有的图神经网络应用在自然语言处理领域的综述
link: Graph Neural Networks for Natural Language Processing: A Survey
另外,本篇博客还包含另外几篇图相关的综述性文章内容:
Graph Representation Learning
Geometric Deep Learning
对于图的机器学习,非常容易想到的就是节点分类,边预测、以及图层级的分类等。对于传统的NLP问题,我们将输入的文本序列表示为图结构时,就可以借助图深度学习技术进行处理。整篇综述根据这一思路从图构造、图表示学习、基于图的Encoder-Decoder模型三方面进行介绍。
图构造
对于AI处理的数据类型,大概可以分类3类:Euclidean Structure、Sequence Structure、Graph Structure。
Eucildean data比如图,Sequence data如文本,这类数据都有一个特点:规则,即排列整齐;而图结构这类非欧几何数据,样本是不规则的,每个样本的邻居节点数量都是不同的,因此图像中的卷积操作就无法在图结构中应用。
针对输入的数据,包括文本、树等,我们根据一定的规则自动化构造构建不同类型的图,如无向图、有向图、多关系图、异构图并使用特点的GNN结构来进行学习。
静态图构建
利用规则或现有的关系解析工具在文本预处理时构造图结构,常见的静态图构建有:
Dependency Graph
依赖图可以用于捕捉给定句子中两个主语之间的关系。对于给定的句子,可以借助现有的解析工具包得到dependency parsing tree,而后抽取出依赖关系,构建dependency graphConstituency Graph
语言学中constituency relation指符合短语结构语法的关系,比如主语NP和谓语VP的关系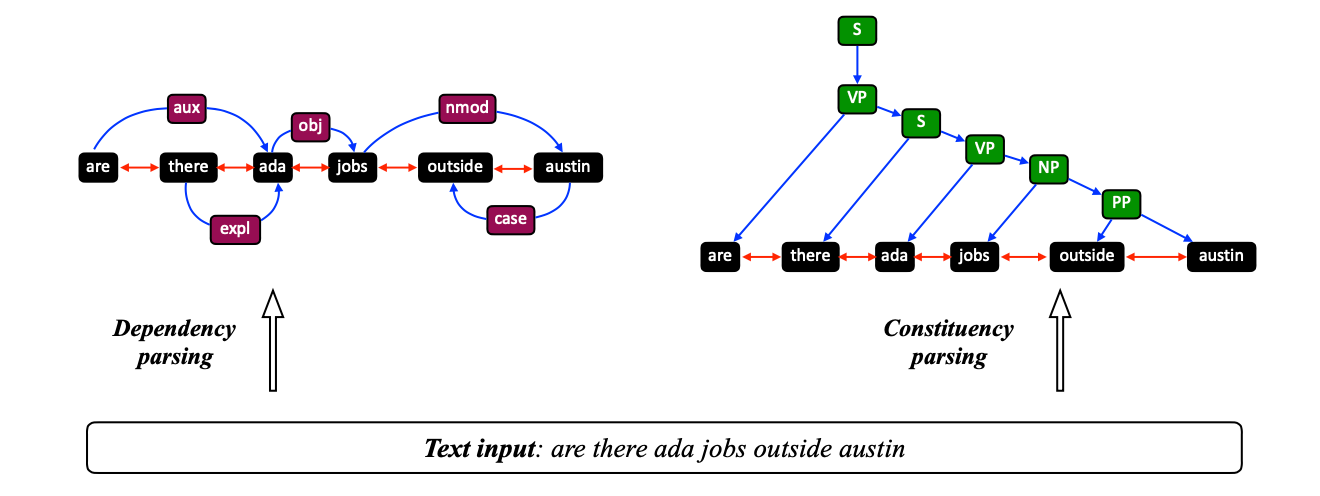
Information Extraction Graph
IE Graph抽取出文本中跨越不同句的结构化的信息。构建IE图首先要提取三元组,而后通过不同三元组间共同参数来确定相同含义的实体进行合并,从而减少节点的数量,消除模糊性。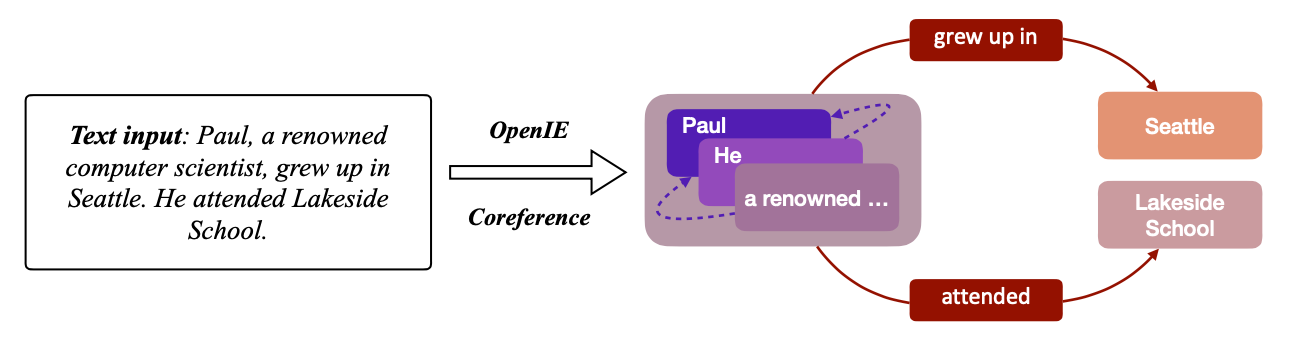
Knowledge Graph
知识图谱能捕获实体以及关系,被广泛用于推理、关系抽取等任务中。知识图谱可以作为文本到embedding之间的一个精练且可解释的中间表示。KG可以表示为 \(\mathcal{G}(\mathcal{V}, \mathcal{E})\),由三元组\(\left(e_{1}, r e l, e_{2}\right)\)。KG在不同的下游任务中起不同的作用,如机器翻译可以用于数据增强,阅读理解中用于构建子图。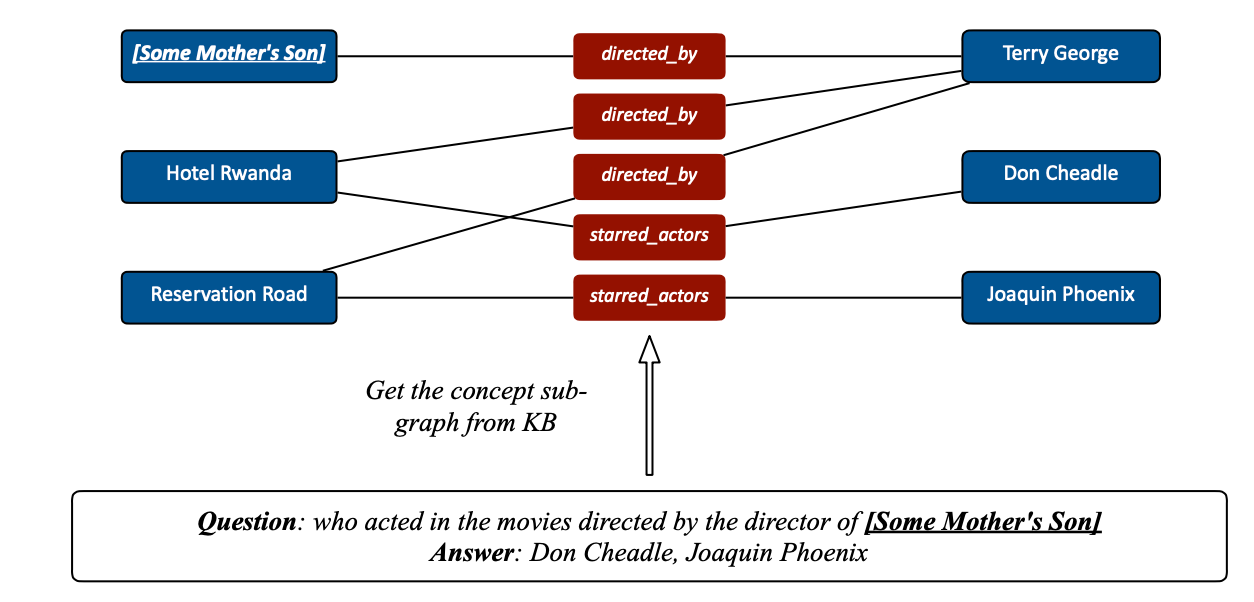
Co-occurrence Graph
共现关系描述了两个词在固定大小的上下文窗口内共现的频率,而后单词和词与词间共现频率构建图。
除了上述几类图构建方法外,针对具体的任务还有很多不同的图构造方法。
动态图构建
静态图可以将数据的部分先验知识编码到图中,但是这需要大量的人力试验以及领域专业知识,且容易包含噪声。另外,静态图的构建是基于构建者自身的经验,得到的并不一定是对于某一下游任务最优的图。
而动态图则是动态学习图结构(加权邻接矩阵),图构造模块和后续图表示学习一起针对下游任务联合优化。图结构学习也是机器学习领域研究的热点问题 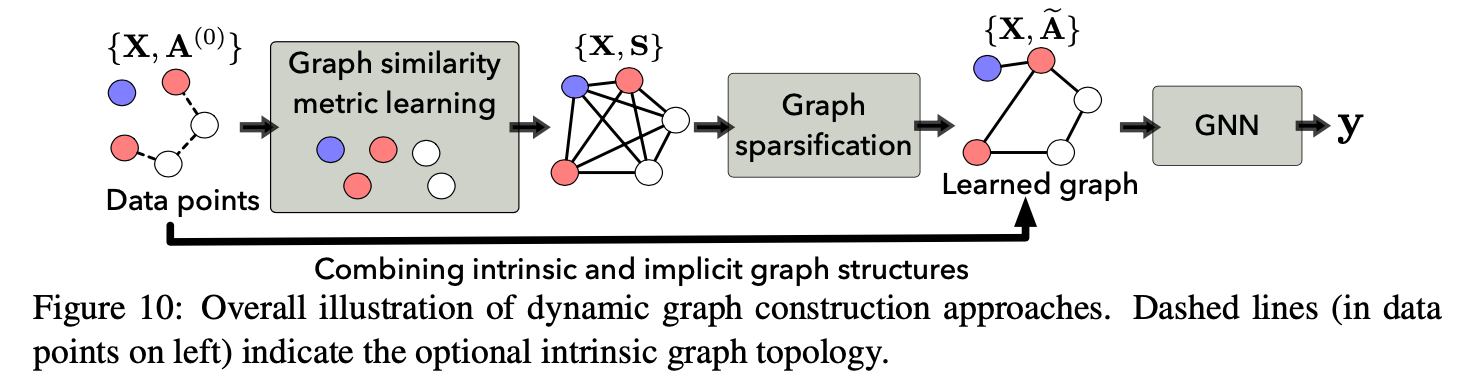
Graph similarity metric learning
图结构学习可以转化为节点相似度度量问题 (相似度矩阵\(S\)),对于相似度度量函数,可以分为两类:
- 基于节点嵌入的相似度度量学习
- 基于结构感知的相似度度量学习
基于节点嵌入的相似度函数通过计算嵌入空间中节点的成对相似度来学习加权邻接矩阵。常见的度量函数包括基于注意力的度量函数和基于余弦的度量函数。 \[ S_{i, j}=\operatorname{ReLU}\left(\vec{W} \vec{v}_{i}\right)^{T} \operatorname{ReLU}\left(\vec{W} \vec{v}_{j}\right) \] 上式为基于注意力的度量函数,\(\vec{W}\)为可学习的权重。类似的,基于cosine的度量函数为: \[ \begin{aligned} S_{i, j}^{p} &=\cos \left(\vec{w}_{p} \odot \vec{v}_{i}, \vec{w}_{p} \odot \vec{v}_{j}\right) \\ S_{i, j} &=\frac{1}{m} \sum_{p=1}^{m} S_{i j}^{p} \end{aligned} \]
基于结构感知的相似性函数在节点信息之外还考虑了边的信息,如 \[ S_{i, j}^{l}=\operatorname{softmax}\left(\vec{u}^{T} \tanh \left(\vec{W}\left[\vec{h}_{i}^{l}, \vec{h}_{j}^{l}, \vec{v}_{i}, \vec{v}_{j}, \vec{e}_{i, j}\right]\right)\right) \] 其中\(\vec{v}_{i}\) 代表节点i的embedding, \(i\vec{e}_{i, j}\) 代表边的embedding $ _{i}^{l}$ 代表节点i在GNN中第i层的embedding, \(\vec{u}\)和\(\vec{W}\) 是可训练的权重。
Graph sparsification
现实世界中大多数的图都是稀疏图,而通过相似度度量函数会得到任意两个节点之间的边,最终生成一个全连通图,这会极大增大开销,并引入噪声,因此需要进行图稀疏化处理。常用的方法包括取k个相似度最高的邻节点,或者给节点间的相似度设定一个阈值。
另外,静态图和动态图也可以结合起来,既可以加速训练,提高稳定性,也能提高下游任务的表现 \[ \widetilde{A}=\lambda L^{(0)}+(1-\lambda) \mathrm{f}(A) \] 上式中\(L^{(0)}\)表示静态图结构,\(\mathrm{f}(A)\)表示可学习的动态图结构。
图表示学习
由于图的类型多种多样,如同构图、异构图、多关系图等等,这些不同的图上进行图表示学习的具体模型或有出入,但总体的步骤和思路基本类似。下面介绍的图表示学习方法是基于同构图,且节点与节点之间仅有一条无向边。
Basic GNN
图神经网络对图中的节点进行embedding,并根据需求给出最终的node embedding或graph embedding。图神经网络的特征传播总体可以分成两个步骤,包括聚合-Aggregation和更新-Update。 \[ \mathbf{m}_{\mathcal{N}(u)}=\operatorname{AGGREGATE}^{(k)}\left(\left\{\mathbf{h}_{v}^{(k)}, \forall v \in \mathcal{N}(u)\right\}\right) \] \[ \operatorname{UPDATE}\left(\mathbf{h}_{u}, \mathbf{m}_{\mathcal{N}(u)}\right)=\sigma\left(\mathbf{W}_{\text {self }} \mathbf{h}_{u}+\mathbf{W}_{\operatorname{neigh}} \mathbf{m}_{\mathcal{N}(u)}\right) \]
其中\(\mathcal{N}(u)\)表示节点\(u\)的邻节点,\(\mathbf{h}_{u}\)则代表节点特征,\(\mathbf{W}\)为可学习的权重矩阵。
Aggregation
聚合操作将节点的邻节点特征进行汇总,常用的方法包括:
Normalization:最基本的聚合方法就是对邻节点embedding求平均,并针对节点的度进行归一化 \[ \mathbf{m}_{\mathcal{N}(u)}=\frac{\sum_{v \in \mathcal{N}(u)} \mathbf{h}_{v}}{|\mathcal{N}(u)|} \]
- Pooling:基于MLP这类的置换不变(permutation invariant)网络进行聚合,通用的pooling aggregator可以表示为: \[ \mathbf{m}_{\mathcal{N}(u)}=\operatorname{MLP}_{\theta}\left(\sum_{v \in N(u)} \operatorname{MLP}_{\phi}\left(\mathbf{h}_{v}\right)\right) \] 另一种Janossy pooling则是赋予邻节点一个次序,并使用对于时序敏感的函数进行聚合 \[ \mathbf{m}_{\mathcal{N}(u)}=\operatorname{MLP}_{\theta}\left(\frac{1}{|\Pi|} \sum_{\pi \in \Pi} \rho_{\phi}\left(\mathbf{h}_{v_{1}}, \mathbf{h}_{v_{2}}, \ldots, \mathbf{h}_{v_{|\mathcal{N}(u)|}}\right)_{\pi_{i}}\right) \]
Attention: 对邻节点分配不同的权重,权重可以基于邻节点的embedding,也可以基于边的权值 \[ \mathbf{m}_{\mathcal{N}(u)}=\sum_{v \in \mathcal{N}(u)} \alpha_{u, v} \mathbf{h}_{v} \] \[ \alpha_{u, v}=\frac{\exp \left(\mathbf{a}^{\top}\left[\mathbf{W h}_{u} \oplus \mathbf{W h}_{v}\right]\right)}{\sum_{v^{\prime} \in \mathcal{N}(u)} \exp \left(\mathbf{a}^{\top}\left[\mathbf{W h}_{u} \oplus \mathbf{W h}_{v^{\prime}}\right]\right)} \]
Updates
在经过多层图神经网络后,某些节点自身的特性会因为不断聚合邻节点的信息而淡化或被抹去,这就导致深度图神经网络的over-smoothing问题。
为缓解over-smoothing问题的一些技巧,比如Concatenation和Skip-Connections等在节点信息聚合后的更新操作入手。 \[
\text { UPDATE }_{\text {concat }}\left(\mathbf{h}_{u}, \mathbf{m}_{\mathcal{N}(u)}\right)=\left[\text { UPDATE }_{\text {base }}\left(\mathbf{h}_{u}, \mathbf{m}_{\mathcal{N}(u)}\right) \oplus \mathbf{h}_{u}\right]
\]
Graph Convolutional Networks (GCN)
图卷积就如同CV中的卷积,被提出后受到了广泛关注和研究。欧氏空间中的离散卷积我们很好理解,而对于非欧数据中的卷积,它的提出流程可以概括为:图信号处理GSP学者提出图的Fourier Transformation,进而得到Graph convolution,从而拓展到神经网络的图卷积网络。
图的卷积定义在spectral domain,相应的邻接矩阵\(A\)用图的Laplacian 矩阵\(L\)替代。\(L = D - A\),\(D\)为度矩阵。把传统的傅里叶变换以及卷积迁移到Graph上, 核心工作就是把拉普拉斯算子的特征函数 \(e^{-i \omega t}\) 变为Graph对应的拉普拉斯矩阵的特征向量。这其中具体的推导过程在此不再赘述。基本的GCN中第k层可以写为下式: \[ \mathbf{H}^{(k)}=\sigma\left(\tilde{\mathbf{A}} \mathbf{H}^{(k-1)} \mathbf{W}^{(k)}\right) \] 其中\(\tilde{\mathbf{A}}=(\mathbf{D}+\mathbf{I})^{-\frac{1}{2}}(\mathbf{I}+\mathbf{A})(\mathbf{D}+\mathbf{I})^{-\frac{1}{2}}\),是拉普拉斯矩阵的一个变形形式。
GraphSAGE
GraphSAGE这一图模型是归纳式 (inductive) 学习。不同于之前的transducer模型,GraphSAGE的目标不是学习到每个节点的embedding,而是学习生成embedding的聚合函数。 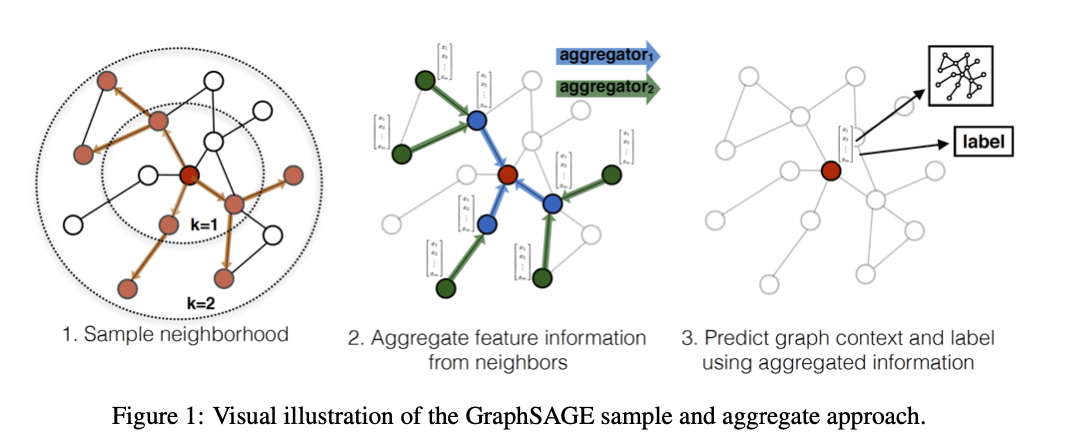 整个框架如上图所示,包括采样、聚合、预测三个步骤。在采样时会选择恒定数量的邻节点,且不仅仅选择1-hop的节点,而是考虑multi-hop。
整个框架如上图所示,包括采样、聚合、预测三个步骤。在采样时会选择恒定数量的邻节点,且不仅仅选择1-hop的节点,而是考虑multi-hop。
基于图的Encoder-Decoder模型
Encoder-Decoder是深度学习模型中非常常见的架构,因此到了图深度学习领域,图到树、graph-graph等模型也应运而生。
Graph-to-Sequence Model
这类模型通常用GNN作为Encoder,RNN/Transformer作为Decoder。此外,这类模型中多使用CNN进行节点特征初始化,用于捕捉GNN不敏感的连续词的潜在信息。这类模型在多关系图或异构图的处理上有所局限。
Graph-to-Tree Model
类似端到端的模型,在NLP任务中,树也具有很强大的表达能力。由于树广义上来讲也是一种图,因此Graph-Tree这类模型的核心在于借助self-attention进行获取局部邻节点的权重,再由decoder 生成包含语义的tree结构。这类模型的应用比如语义解析、数学应用问题(模型输出为由树来表示的方程)。
Graph-to-Graph Model
补充
图神经网络在NLP中的下游任务
已有的基于图相关技术的NLP任务包括自然语言生成、机器翻译、情感分类、文本分类、知识图谱补全、信息抽取(命名实体识别、关系抽取)、自然语言推理、解数学问题(文本)等
关于图的semi-supervised
对于监督学习,如一个分类问题,我们的样本需要满足i.i.d assumption:样本之间是独立同分布的(不然还需要建模样本之间的联系)。然而在图结构上做诸如节点分类问题时,节点之间相互联系,且这些联系在节点分类中起到了重要的作用。因此基于图的很多深度学习是semi-supervised。这意味着在训练图模型时,我们利用了测试节点的信息,但不包括label。
深度学习模型的迁移
近几年随着图神经网络的兴起,许多人都涌向这块处女地,深度学习模型中的一些经典思想和模型也被迁移到图相关的模型中,比如基于self-attention的GAT、GraphGAN、Graph Transformer等。另外,在NLP落地的经典搜索、广告、推荐算法中,图神经网络也被广泛应用。
GraphGAN: Graph Representation Learning with Generative Adversarial Nets
Graph Transformer for Graph-to-Sequence Learning
