Encoding Word Order in Complex Embeddings
Code: link
概要
针对位置编码提出的改进,切入点新颖高效且为位置编码带来了一定的具体意义和可解释性。传统的位置嵌入捕获单个单词的位置,而不是单个单词位置之间的有序关系(例如邻接关系或优先级)。本文提出的方法建模单词的全局绝对位置和它们的顺序关系,将以前定义为独立向量的词嵌入推广到变量(位置)上的连续词函数。每个单词的表示会随着位置的增加而移动。因此,在连续函数中,不同位置的词表示可以相互关联。将这些函数的通解推广到复值域,得到了更丰富的表示。作者在文本分类、机器翻译和语言模型方面进行实验,取得了良好的表现。
Positional encoding
Positional encoding 位置编码在transformer中用于存储位置信息(由于self-attention没法获取序列位置的信息),此外BERT中encoding部分也包含了位置编码。对于位置编码,本能的想法是针对序列中的每个位置必须是独一无二的,且不受序列长度的影响。常见的positional encoding的方法有:
- 绝对(正弦)位置编码(Sinusoidal Position Encoding)
- 相对位置编码(Relative Position Representations)
- 可学习位置编码
正弦位置编码
Transformer中使用的就是这种编码,实际上具体编码过程使用了正弦和余弦。具体公式为: \[ \begin{aligned} P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}} \right) \\ P E_{(p o s, 2 i+1)} &=\cos \left(p o s / 10000^{2 i / d_{\text {model }}} \right) \end{aligned} \] 其中\(d_{model}\)为输入词向量的维度。如d(model)=128,那么位置3对应的位置向量为 \[ \left[\sin \left(3 / 10000^{0 / 128}\right), \cos \left(3 / 10000^{1 / 128}\right), \sin \left(3 / 10000^{2 / 28}\right), \cos \left(3 / 10000^{3 / 28}\right), \ldots\right] \] 在具体的应用时可能前一部分用正弦后一部分用余弦。

相对位置编码
Todo
Self-Attention with Relative Position Representations
可学习位置编码
Todo
Intro
本文的重点在于建模文本信息中额外的词的内部顺序和相邻关系,对比原本位置编码方式仅编码词的位置。模型将之前定义为独立向量的词嵌入扩展为位置自变量上的连续函数。在一个连续函数中,不同位置的词表示可以相互关联。
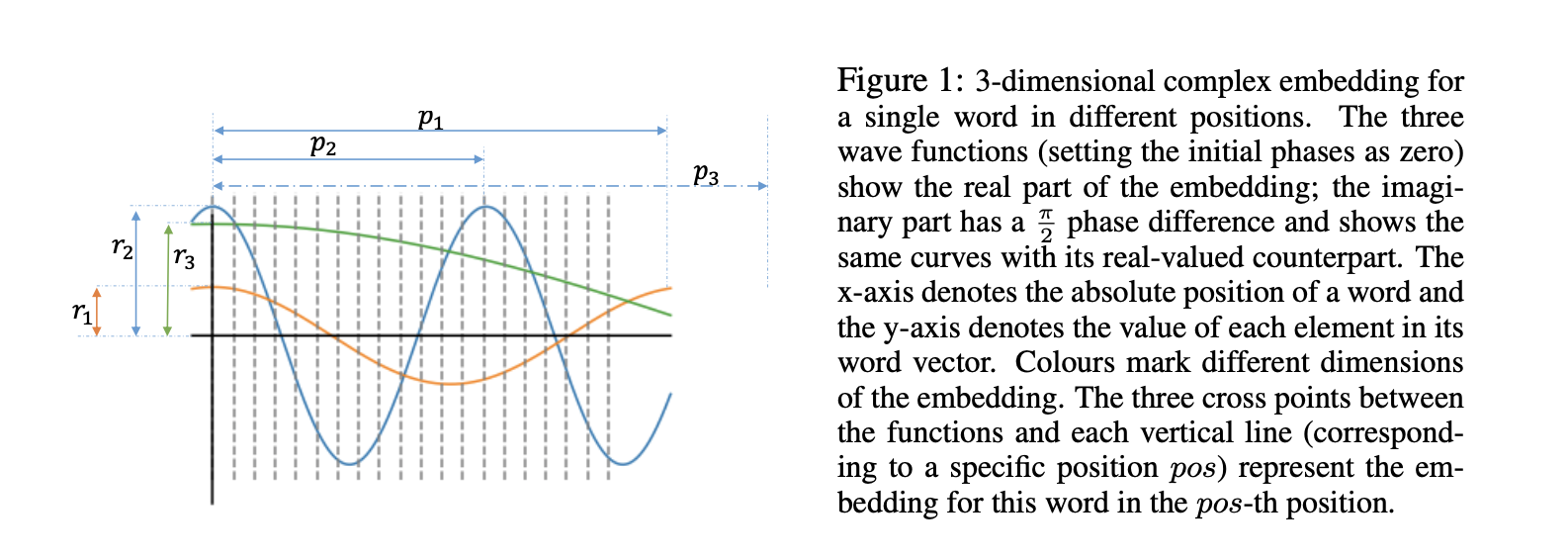
Methodology
类似于Word Embedding,位置编码(PE)定义了一个映射关系,将词的序列索引映射为一个向量。\(f_{n e}: \mathbb{N} \rightarrow \mathbb{R}^{D}\)。最终某个词的embedding通常表示为为词向量和位置向量的和: \[f(j, p o s)=f_{w e}(j)+f_{p e}(p o s)\]
论文中提出了一个位置独立问题(position independence problem),即位置编码无法捕获相邻词以及其顺序之间的潜在关系。而当后续用于特征处理的网络对这类信息不敏感时,这一问题就会限制整个模型的表达能力。相对位置编码针对这一问题进行了一定的研究,但其无法涵盖整个序列域。
性质
论文指出了在位置编码中建立词序模型所必需的性质。
由于位置向量中每个维度的值都是根据离散的位置index得到的,这使得位置间有序关系建模变得困难,因此需要根据位置索引构建一个连续的函数(以在每个维度中表示一个特定的单词?) \[
f(j, \text { pos })=\boldsymbol{g}_{j}(\text { pos }) \in \mathbb{R}^{D}
\] \(g_j\)即\(\boldsymbol{g}_{w e}(j) \in(\mathcal{F})^{D}\),词\(w_j\)在pos位置可以表示为 \[
\left[g_{j, 1}(\operatorname{pos}), g_{j, 2}(\operatorname{pos}), \ldots, g_{j, D}(\text { pos })\right] \in \mathbb{R}^{D}
\] 当词\(w_j\)从pos位置转到pos’位置时,只需要改变自变量的值而不需要改变映射函数\(g_j\)。
函数
由于实数也被囊括在复数域中,且前人有相关工作(详见论文原文Section2.2)验证了复数域所具有的更强大的表达能力,作者将模型拓展到了复数域。对于理想的映射函数,论文中提出了两条性质,即:
- Position-free offset transformation
- Boundedness
变换函数\(Transform\)需满足对于任何pos,有 \[ g(p o s+n)=\operatorname{Transform}_{n}(g(p o s)) \] 满足等式的变换函数被称为witness,而满足这一条件的映射函数\(g_j\)则被称为linearly witnessed。规定Transform \((n\), pos \()=\) Transform \(_{n}(\) pos \()=w(n)\)。另外,映射函数\(g_j\)需要有界。
而后作者证明了满足上述性质的映射函数唯一解为 \[ g(p o s)=z_{2} z_{1}^{p o s} \text { for } z_{1}, z_{2} \in \mathbb{C} \text { with }\left|z_{1}\right| \leq 1 \] 对于任意的 \(z \in \mathbb{C}\), 我们可以写成 \(z=r e^{i \theta}=r(\cos \theta+i \sin \theta)\),因此上式可写为: \[g(p o s)=z_{2} z_{1}^{p o s}=r_{2} e^{i \theta_{2}}\left(r_{1} e^{i \theta_{1}}\right)^{p o s}=r_{2} r_{1}^{p o s} e^{i\left(\theta_{2}+\theta_{1} p o s\right)} \quad$ subject to $\left|r_{1}\right| \leq 1\]
(...跳过证明和优化过程)
最终的位置编码函数\(f(j\), pos \()\)为 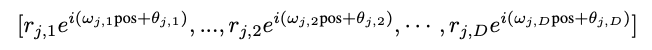 \(j\)代表单词(索引),\(pos\)表示位置索引。
\(j\)代表单词(索引),\(pos\)表示位置索引。
对于embedding中的每一维度,都有各自的参数,振幅r、频率p、初相\(\theta\),这些参数是trainable的。此外,周期/频率决定了单词对位置的敏感程度。当周期很短,则说明嵌入将对position高度敏感。注意,振幅、频率是与postion(自变量)无关的,与单词和维度有关。此时,word embedding可以用这些参数来表示(维度与positional embedding维度相同)。
实验
作者在文本分类、机器翻译和语言模型几个任务上进行了实验,分别用Fasttext、LSTM、CNN、Transformer作为模型的backbone,而后使用不同的位置编码方法以及本文的Complex-order编码方法进行embedding,对比几个实验结果均取得了可观的提升。而计算开销(时间)上并没有显著的增加。  实验基于tensorflow,目前没有pytorch版本,笔者将会尝试将其迁移到pytorch框架下并开源。
实验基于tensorflow,目前没有pytorch版本,笔者将会尝试将其迁移到pytorch框架下并开源。
相关工作
Vanilla Position Embeddings
Trigonometric Position Embeddings
Todo
