Pre-training of Deep Bidirectional Transformers for Language Understanding
Transfromer
关于Bert,多的不说了,网上的扫盲帖、详解帖也一大堆。我们针对源码来一步一步的看。
Transformer部分的源码来自于pytorch-transformer
首先是Multi-head Self-Attention,这也是Transformer中最重要的一部分。 \[ \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \]

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61class MultiHeadAttention(nn.Module):
def __init__(self, hidden_size, dropout_rate, head_size=8):
super(MultiHeadAttention, self).__init__()
self.head_size = head_size
self.att_size = att_size = hidden_size // head_size
self.scale = att_size ** -0.5 # d_k ^ 0.5
self.linear_q = nn.Linear(hidden_size, head_size * att_size, bias=False)
self.linear_k = nn.Linear(hidden_size, head_size * att_size, bias=False)
self.linear_v = nn.Linear(hidden_size, head_size * att_size, bias=False)
initialize_weight(self.linear_q)
initialize_weight(self.linear_k)
initialize_weight(self.linear_v)
self.att_dropout = nn.Dropout(dropout_rate)
self.output_layer = nn.Linear(head_size * att_size, hidden_size,
bias=False)
initialize_weight(self.output_layer)
def forward(self, q, k, v, mask, cache=None):
orig_q_size = q.size()
d_k = self.att_size
d_v = self.att_size
batch_size = q.size(0)
# head_i = Attention(Q(W^Q)_i, K(W^K)_i, V(W^V)_i)
q = self.linear_q(q).view(batch_size, -1, self.head_size, d_k)
if cache is not None and 'encdec_k' in cache:
k, v = cache['encdec_k'], cache['encdec_v']
else:
k = self.linear_k(k).view(batch_size, -1, self.head_size, d_k)
v = self.linear_v(v).view(batch_size, -1, self.head_size, d_v)
if cache is not None:
cache['encdec_k'], cache['encdec_v'] = k, v
q = q.transpose(1, 2) # [b, h, q_len, d_k]
v = v.transpose(1, 2) # [b, h, v_len, d_v]
k = k.transpose(1, 2).transpose(2, 3) # [b, h, d_k, k_len]
# Scaled Dot-Product Attention.
# Attention(Q, K, V) = softmax((QK^T)/sqrt(d_k))V
q.mul_(self.scale)
x = torch.matmul(q, k) # [b, h, q_len, k_len]
x.masked_fill_(mask.unsqueeze(1), -1e9)
x = torch.softmax(x, dim=3)
x = self.att_dropout(x)
x = x.matmul(v) # [b, h, q_len, attn]
x = x.transpose(1, 2).contiguous() # [b, q_len, h, attn]
x = x.view(batch_size, -1, self.head_size * d_v)
x = self.output_layer(x)
assert x.size() == orig_q_size
return x
1 | class EncoderLayer(nn.Module): |
Decoder的结构与Encoder基本类似,不过输入还包含Encoder的输出以及之前序列的输出结果,另外Decoder的自注意力层只允许关注输出序列之前的位置(通过-inf在self-attention计算中的softmax部分进行mask)
1 | class Transformer(nn.Module): |
Bert
先来看一下论文的摘要:
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
这里可以把Bert的核心概括为几个点,首先是Pre-trained model——借助未标记数据进行训练,针对具体任务做fine-tune,其次是编码上下文,而不是单侧的。
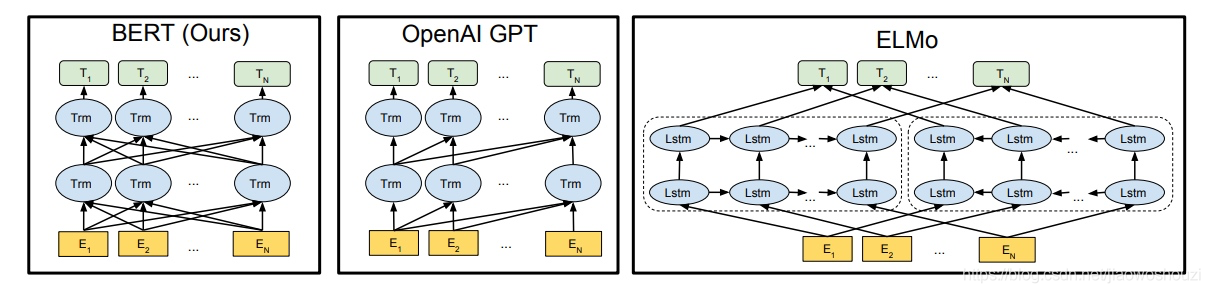
上图展现了几个Pre-train model的结构对比,ELMo借助了LSTM作为编码器,介于LSTM对比Self-attention的劣势,这一模型可以看作只关注上下文的Bert,而GPT则是单向语言模型,对比Bert相当于把Encoder layer换为Decoder layer,也就获得了对应的单向视野。而Bert的Transformer,其实也就是相当于n个Encoder的堆叠。
the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
1 | # Bert中的Transform block |
在Bert原论文中,Bert的Bidirectional还体现在具体的训练任务上:
Unlike left-toright language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
具体来说,训练任务包括两个,一是Masked Language Model,另一个是Next Sentence Prediction用于理解两个句子间的关系
对于具体下游任务来说,句子层面的我们可以取[CLS]的vector并做Softmax之类的操作。利用bert获取上下文相关的词向量则可以针对某个token,取其所在位置对应的某些层的hidden states,然后做特征融合(Feature-based)。
