简介
本项目构建的漫威人物知识图谱基于美国漫威漫画公司制作的一系列漫画和电影组成的架空世界和共同世界。基于我们构建的知识图谱,用户可以结构化的查询人物信息,了解角色间的关系以及漫威超级英雄全貌,更深入地了解漫威宇宙。项目面向百科的中文人物领域知识构建图谱,所选人物范围为漫威人物,包括复仇者联盟、神盾局特工与反派等角色类别。最终通过neo4j数据库完成了整体框架的可视化。图谱数据基于百度百科、维基百科以及漫威人物数据网页。
本体构建
本体是用于描述一个领域的术语集合,其组织结构是层次结构化的,可以作为一个知识库的骨架和基础。
1. 领域:「漫威人物」;
2. 基本术语: 「超级英雄」、「反派」等等概念
3. 关系:超级英雄之间为朋友关系,反派与超级英雄之间为敌对关系,另外也存在一些情人/爱人关系。
4.类别:复仇者联盟、神盾局特工、银河护卫队、超级反派、其他
5.属性:中文/英文名、性别、登场作品、所属团队等
事实抽取
百科数据中,有许多关于漫威人物的信息,其中有不少冗余信息,如人物冗长的经历与生平等。以百度百科为例,有用的信息为人物之间的关系、阵营,人物的基本信息以及能力值的表格。
利用网上爬取的方式,在漫威人物网站中爬取人物人名信息。接着利用词条分类的方法,观察各个词条与漫威之间的关系,发现“漫威”二字本身不可用于唯一标识,但是“漫威旗下”或者“美国漫威漫画旗下”这些字眼却可以对漫威人物进行唯一性筛查。所以我们依据人名进入百度百科的多义词界面,根据关键词"美国漫威漫画旗下"或"漫威旗下"进行正则化筛选,从而得到有用的URL,将其保存于Excel表格之中,为之后的爬取工作提供正确的URL网址。 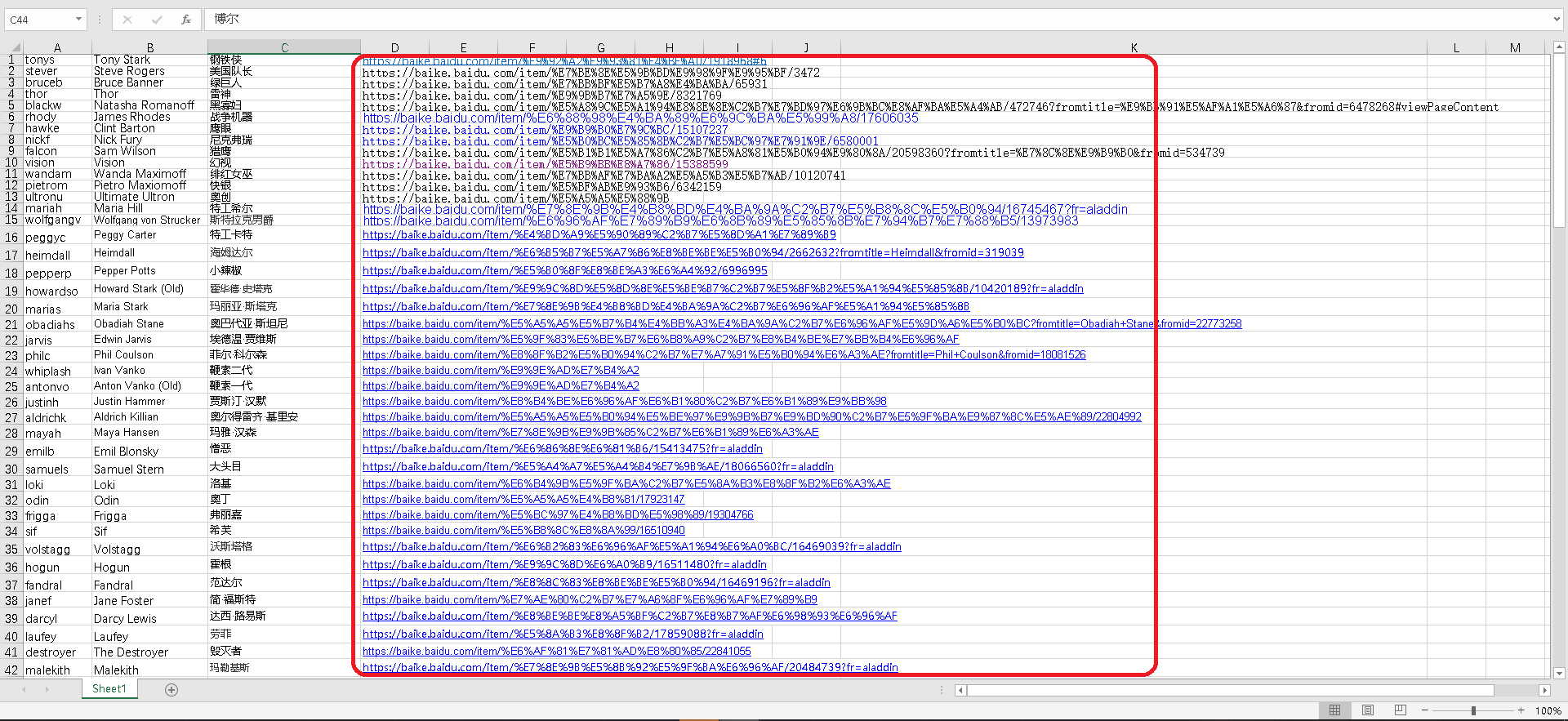
人物信息抽取
对于漫威人物的基本信息,我们首先利用百科的Infobox进行爬取。找到百科页面查看源网页得知,Infobox的值以basicInfo-item value作为标签存储,因此代码如下: 1
2key = soup.find_all(class_="basicInfo-item name")
val = soup.find_all(class_="basicInfo-item value")
利用源网页信息中的标签可以知道,表格信息是存储在 1
<table log-set-param="table\_view" data-sort="sortDisabled">
人物图片爬取
得到人物基本信息与关系三元组以后,我们将百科界面中漫威人物对应的图片爬取下来,存储于后端,在查询时显示出来,提供一个较好的可视化效果。 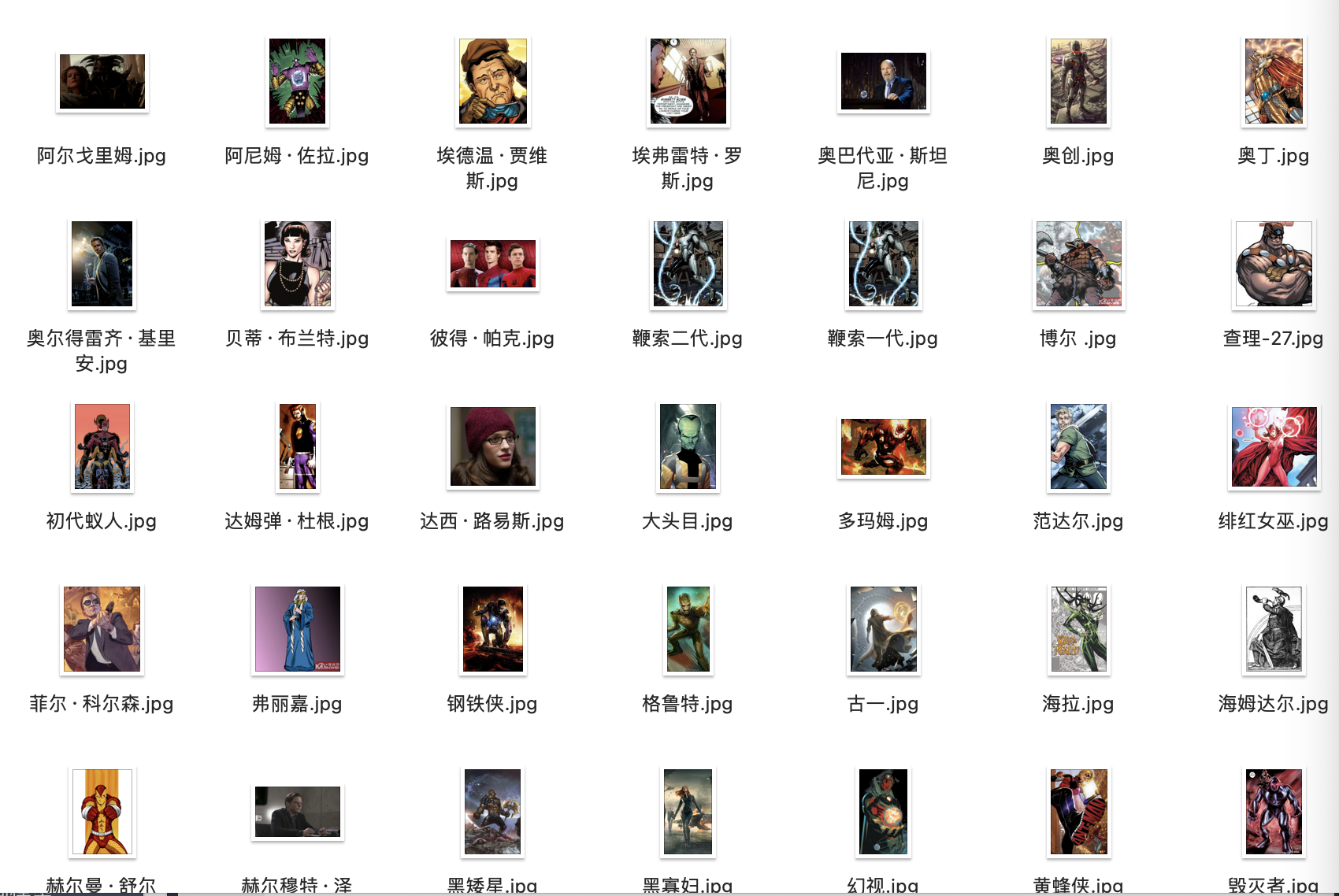
三元组
对于构建的知识图谱中人物关系三元组,主要数据源于外网某一漫威人物数据库,我们爬取其网站中存储的三元组csv文件,构建如( 美国队长, 朋友 , 钢铁侠 )形式的人物关系三元组,但是由于该网站最后更新时间为2018年,且其人物关系是基于上映的漫威系列电影,导致该部分的人物关系存在时效滞后、内容不完整等问题。因此基于已有三元组关系,我们进一步通过DeepKE从爬取的百度百科中的角色经历中进行关系三元组抽取,将得到的三元组与原有的进行更正与补充。
DeepKE是基于深度学习的开源中文关系抽取工具,我们对其中基于CNN、Transformer、RNN三个网络的关系抽取模型进行实验。在去年知识表示与推理课程中,漆桂林老师带领我们进行了知识抽取框架实践,根据实验结果我们发现对于是否给定头尾实体,三元组抽取的效果会有很大差别。因此在进行抽取时,我们将已有三元组的主语和宾语作为head和tail。另外,在爬取的人物角色经历中,对于冗长的文本,我们使用正则表达式对主语和宾语都在某一句中出现的句子做关系抽取。
关系抽取数据集来源于苏州大学开源人物关系数据集。我们先对数据做预处理,筛除掉无效的字符标点,以及数字等冗余信息,并将实体对进行编码,这可以避免模型学习对实体词过分关注以至于导致bias。我们采用了one-hot编码,将每个token映射为一个id,构建词典存储所有的token。最终可以把关系抽取出来,此处展示几个范例。将得到的关系与原本的关系进行对比,若两者存在不同,则进行人工判断,确认哪个关系是准确的。
类别推断
知识图谱中,类别信息(Type Information)是一种特殊的三元组, 其具体表现为: \[ instance \stackrel{type}{\longrightarrow} concept \] 在项目构建的漫威人物知识图谱中,由于这一任务属于特定领域的知识构建,所以我们根据类别推断的方法和目标进行一定的延伸,使用类别推断来进行漫威人物所属的组织的判断,具体的类别包括复仇者联盟、神盾局特工、银河护卫队、超级反派等。
在知识图谱构建中,项目结合了两种类别信息推断的方式,包括: - Type Inference from Infoboxes - Type Inference from Text
分析从百度百科得到的infobox,部分漫威人物的infobox中有“所属团队”这一属性,对于有该属性的人物,我们通过爬取的网页信息,用xpath解析后使用正则表达式匹配这一属性,抽取出其属性值,即该人物所属团队。
部分人物的infobox中不存在“所属团队”这一属性。对于这些人物,我们选择从文本中进行类别提取,即通过识别轻量级语法模式进行提取。
从百度百科提取的人物infobox中,我们可以从人物经历中推断如否加入了诸如神盾局特工、复仇者联盟等团队,如 A 加入了 B(复仇者联盟、神盾局特工),其判断的正则表达式如下: \[ pattern = re.compile('(.*)[\u52a0][\u5165](.*)[\u590d][\u4ec7][\u8005](.*)\$') \]
对所有数据使用上述算法处理后,对没有不符合上述类别的归类为其他,并对得到的类别信息进行数据清洗和检查,去除了百科文本中的几个错别字并进行同义词合并,得到五个类别,对类别进行编码后保存到json文件中,后续将使用该信息在Neo4j中进行可视化。
知识融合
知识融合目标是融合各个层面(概念层、数据层)的知识 ,基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来
数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的知识库对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤,我们用beautifulsoup解析爬取的网页,过滤掉多余信息,只保留infobox,基本信息等数据,整合为key-value的形式并保存在json文件中。得到json文件后,英文,注释,网页中原有的错误,空格,符号等问题使用正则表达式和手动替换的方式调整。
由于中文维基百科的数据较少,所以我们的知识图谱以百度百科的数据为主体构建,将维基百科的数据融合进百度百科。
问答
智能问答系统以一问一答形式,从数据库中定位用户所需要的提问知识,通过与用户进行交互,为用户提供个性化的信息服务。我们在知识抽取任务得到的三元组关系的基础上,附加知识融合得到的infobox以及从百科上爬取的漫威角色图片,实现了一个问答系统。
对于KB-QA问题,首要任务是如何将用户查询的语句转换成数据库可识别的问题,转换的同时还需要保证转换的高准确率。而高准确率的基础,则是表现良好的分词模型。
例如,当用户提出一个问题:"绿巨人的爱人是谁?”时,我们需要对文本数据进行处理。通过进行分词、词性标注等操作,我们能提取出关键字。在上面的问句中,我们通过词性标注可以得到:
\[ ['绿巨人/nr', '的/deg', '爱人/n', '是/vc', '谁/pn'] \]
类似地,用户所有的查询都可以进行同样操作。在阅读大量文献后,我们选择了两种模型进行实现。一种是被广泛使用的中文分词模型LTP,另一种是ACL2020新提出的命名实体识别模型FLAT。
LTP
LTP是基于词性标注、依存语法分析的一种分词模型。其本质可以视作一个感知机。这种通过结构化感知器训练的经典模型在多个中文分词数据集上都取得了较好的效果。
FLAT
在我们构建的知识图谱中,有许多实体词条在日常生活中易出现歧义。如对于"美国队长"一词,我们很容易将"美国"和"队长"分成两个实体。所以,在用户查询语句中,我们应该重点关注命名实体识别问题。
FLAT是一种表现SOTA的命名实体识别模型。它是一种基于汉字格结构和Transformer的模型。汉字格结构思想的提出已有较长时间。汉字格结构是指我们可以将一个句子与一个词典进行匹配,得到其中的潜词,从而得到一个有向无环图,其中每个节点都是一个字符或一个潜在的字。格包括句子中的一系列字符和可能的单词。它们不是按顺序排列的,单词的第一个字符和最后一个字符决定了它的位置。在汉字格结构的基础上,FLAT提出了一种新的编码方式,将一句话的格之间的位置编码并扩展成平面。句子的编码再送入transformer进行进行训练。
我们在MSRA上进行了模型训练,模型测试准确率达到了0.94。最终我们结合FLAT、字典匹配、LTP进行人物名称识别和分词,共同完成了任务。
推荐系统
我们使用中文维基百科语料以及爬取到的漫威人物文本资料做了embedding,并根据word2vec构建了漫威人物推荐系统,输出与用户输入人物距离最近的人物。完整处理过程包括解析中文维基百科文件,繁体简体转化,数据清洗,中文分词,Gensim词嵌入模型训练。
对于中文分词模块,考虑人物名字以及特殊能力等名词分词存在较大难度,我们复现了SOTA中文分词,并与jieba分词的效果做了对比实验。
中文维基百科数据来源于 zhwiki-20210301-pages-articles.xml.bz2 文件。先用Gensim库中的WikiCorpus()函数对其进行处理,得到繁体中文维基语料的txt文件。对于繁体中文,我们需要将其转化为简体中文。应用python中的opencc库(Open Chinese convert)对繁体维基百科文件按行进行t2s处理,同时将txt文件中的 t, n等字符进行清洗,得到中文简体维基语料。另外在分词处理前,用iconv()函数处理文件中的非utf-8字符。
分词处理时,我们选择了Tian等人发表在ACL2020中的中文分词SOTA模型\(WMS_{EG}\),其在MSR、PKU等数据集上的OOV Recall比之前的模型提高了约3%。这一套分词模型在传统encoder-decoder模型中增加了Memory Network。我们复现模型时,选择ZEN作为encoder、crf作为decoder,并用项目提供的WMSeg.ZEN.PKU预训练模型进行分词,在应用前我们在简单语句上进行测试,分词结果良好。

根据得到的分词结果,我们使用开源的第三方Python工具包Gensim进行word2vec模型训练,设定词向量维度为400,模型为CBOW连续词袋模型。在服务器上,workers数量为32,训练时长约1h。
可视化
知识图谱构建完成后,我们将其进行了可视化展示。可视化展示基于Neo4j图形数据库。在于Neo4j框架下,每一个实体都以一个节点的形式呈现,整体数据以结构化数据存储在网络中。在图形数据库的基础上,我们进行了实体与实体间关系、知识问答的可视化实现。同时,为了能够更好地让知识图谱服务于用户,我们以网页的形式展示图形数据库。在前端部分,我们进行了一些CSS修饰工作。 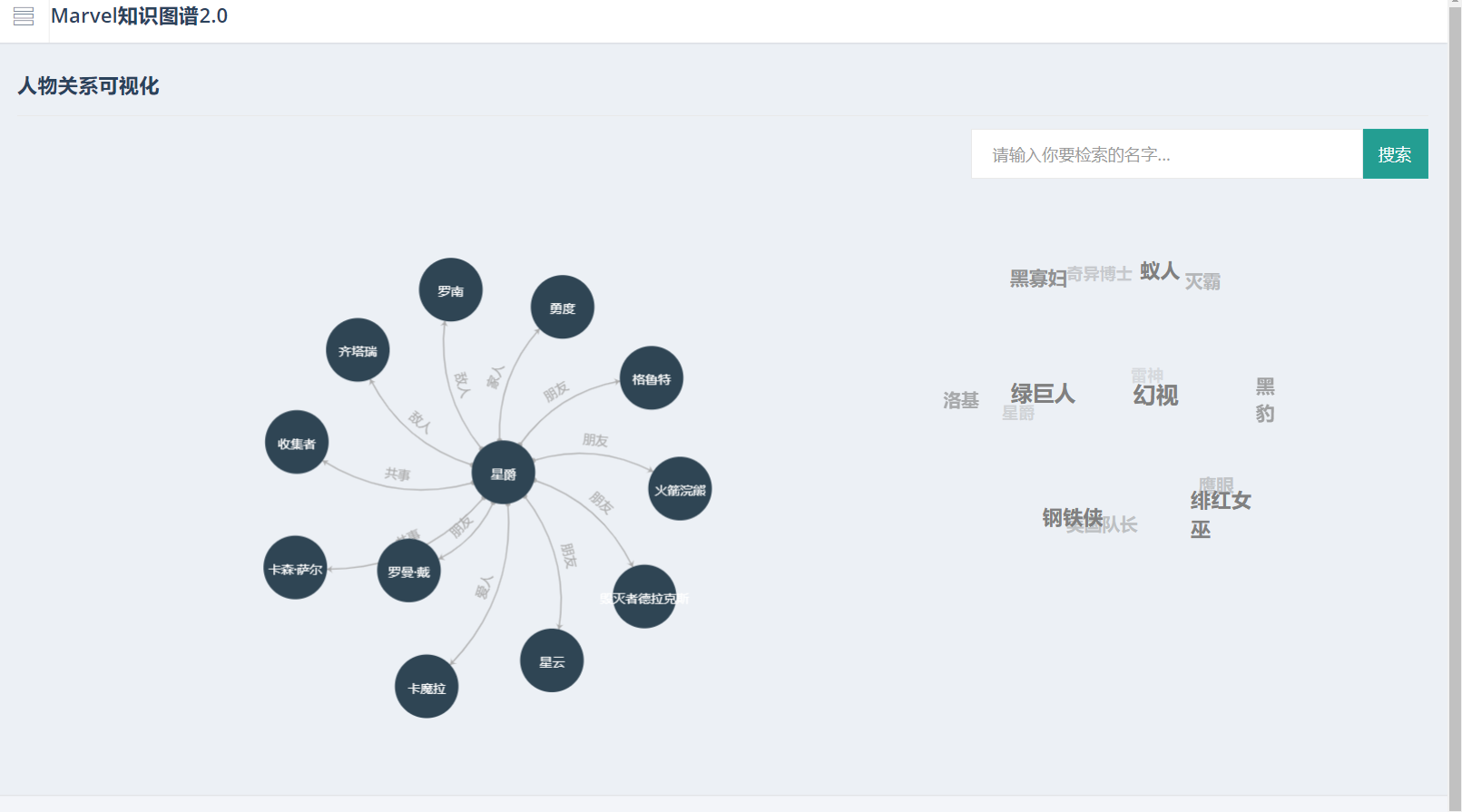

后记
本项目为知识图谱课程设计的小组作品。整个项目数据量不大,且所实现的功能也没有涉及到一些sota的模型或现在主流的技术,也借鉴了部分网上的开源代码,最后课程得分也只有88(跟我大学四年均分一样)。不过这个课程设计让我结实了一群有趣的朋友,收获了珍贵友谊,与之对于什么项目经历倒也显得微不足道了。
